Примерно в середине 2025 года команда ученых из Колумбийского университета, частично профинансированная Управлением перспективных оборонных проектов (DARPA — той же организацией, которая, среди прочего, подарила миру интернет), создала «устройства, способные увеличиваться за счет поглощения других машин». Речь, разумеется, идет не о буквальном переваривании, а скорее об интуитивной механической самосборке: базовые цилиндрические роботы Truss Link, которые могут передвигаться благодаря выдвижным магнитным стержням на концах их трубчатых корпусов, сначала беспорядочно носятся по поверхности, затем случайным образом соединяются — и оказывается, что в виде упорядоченных структур (треугольников, потом тетраэдров и так далее) им энергетически выгоднее менять свое положение в пространстве как единому целому. «Поглотив» таким образом несколько базовых роботов — на деле собрав себя из них, — получившийся трансформер движется быстрее и грациознее, чем раньше. Более того, этот механический вольвокс обрел способность расти, восстанавливаться и приспосабливаться к окружению — благодаря программному алгоритму, который его создатели назвали «роботизированным метаболизмом». Это прямой шаг по пути, проложенному биологической эволюцией: для живых существ умение адаптироваться — ключ к выживанию. Исследователи проводят параллель с аминокислотами: поедая другие организмы (и усваивая, в частности, те самые аминокислоты в процессе пищеварения) либо напрямую встраивая в себя чужой генетический код, живые существа улучшают свою приспособляемость. «В конечном счете нам придется обучить роботов делать то же самое — включать в себя других роботов частями или целиком, — заявил Ход Липсон (Hod Lipson), руководитель Лаборатории креативного машиностроения при Колумбийском университете. — Только вообразите безграничные творческие возможности в мире, где ИИ сможет создавать физические конструкции из роботов с той же легкостью, с какой сегодня он составляет для вас электронные письма!»

Трёхмерный робот в форме тетраэдра, к которому присоединилось дополнительное звено, использовал это самое звено в качестве опоры при спуске по наклонной плоскости — и преодолел эту трассу на 66,5% быстрее «чистого» тетраэдра, составленного из тех же элементов Truss Link (источник: Columbia University)
Очевидно, что обучить искусственные сущности взаимодействию и эволюции в цифровом пространстве даже легче, чем в физической реальности. Ключевое условие — обеспечить их средой, подходящей для обмена фрагментами (в данном случае исключительно информационными). В мае 2026 года стало известно о планах Linux Foundation изменить общепринятую распределённую открытую инфраструктуру системы доменных имён (DNS), чтобы упростить ИИ-агентам обнаружение себе подобных в интернете. Вместо традиционного сканирования портов и обращения к человекочитаемым веб-страницам, что увеличивает нагрузку на сетевую инфраструктуру, агенты и серверы, работающие с протоколом контекста модели (model context protocol, MCP), в рамках предлагаемого проекта DNS-AID будут использовать DNS как глобальный и децентрализованный реестр взаимного доступа — своего рода телефонную книгу для прямых коммуникаций между ботами. В частности, DNS-AID предполагает создание специального адреса в формате _index._agents.{domain}, который станет отправной точкой для обращения агентов к веб-ресурсам, чтобы находить друг друга и устанавливать взаимодействие. Это, в свою очередь, приведёт к дообучению агентных моделей и приобретению ими свойств и возможностей, изначально отсутствовавших в их тренировочном массиве.
И это лишь два относительно недавних примера того, как на практике реализуется идея внедрения эволюционного подхода в развитие генеративного искусственного интеллекта. Большие языковые модели (БЯМ) становятся настолько масштабными и сложными, что проектировать их дальнейшее совершенствование вручную с каждым годом всё труднее и затратнее. Поэтому логично опереться на естественную эволюционную концепцию, в успешности которой — на собственном примере — у человечества нет причин сомневаться.
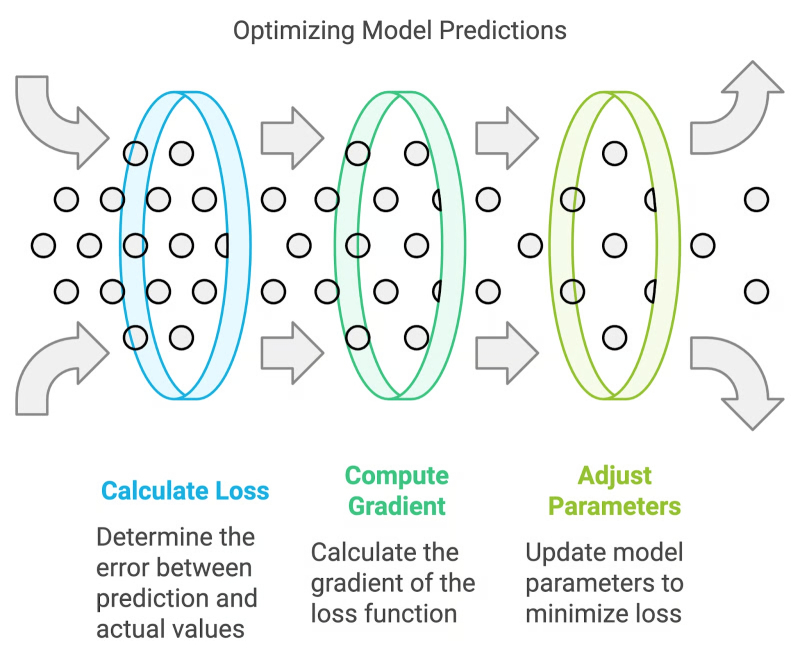
Типичная схема оптимизации ИИ-модели: функция потерь демонстрирует точность прогнозов, которые формирует данная модель. В процессе тренировки корректирующий алгоритм (например, обратное распространение ошибки) задействует градиент функции потерь по отношению к параметрам нейронной сети, чтобы скорректировать эти параметры и минимизировать потери, эффективно улучшая производительность модели на наборе данных (источник: DataCamp)
⇡#Совсем как у животных
Как сегодня оценивают качество алгоритмов ИИ (напомним, что машинное обучение по сути представляет собой генерацию внутри нейросети именно алгоритмов — пусть и неявно заданных, с трудом поддающихся человеческому пониманию; их также называют статистическими процессами, основанными на данных)? Безусловно, существует множество специализированных тестов, сложных практических задач (например, математические проблемы Эрдёша), статистика использования в различных сферах и так далее. Однако наиболее общее представление о работе нейросети формируется благодаря оценке того, насколько успешно она минимизирует функцию потерь — математическое выражение, показывающее, насколько прогнозы модели отклоняются от ожидаемых результатов. Без преувеличения можно утверждать, что алгоритмы, лежащие в основе современных больших языковых моделей, отбираются (не разработчиками вручную, конечно, а в процессе обучения модели) главным образом по критерию эффективности реализации классического градиентного спуска. Да, существуют и ограниченно применимые альтернативы — генетические алгоритмы, байесовская оптимизация, — но, поскольку обучение крупной универсальной нейросети сводится к поиску оптимумов функции в многомерных пространствах её параметров, градиентный спуск по-прежнему остаётся ключевым инструментом.
Нейроэволюционный метод представляет собой практическое применение идей дарвиновской эволюции (наследственности и изменчивости под воздействием внешних условий) для улучшения алгоритмов ИИ — и формально он вовсе не требует отказа от градиентного спуска. Однако акцент переносится с совершенствования самого этого подхода на повышение итоговых результатов, которые он позволяет достичь; на оценку условной эффективности больших языковых моделей — её можно измерять по баллам, полученным на синтетических тестах, количеству решённых за определённое время задач Эрдёша, снижению частоты галлюцинаций в ответах и так далее. Проще говоря, на передний план выходит симуляция естественного отбора: алгоритмы ИИ, создаваемые в ходе обучения модели, должны мутировать и затем проходить отбор так же, как живые организмы в своей природной среде.
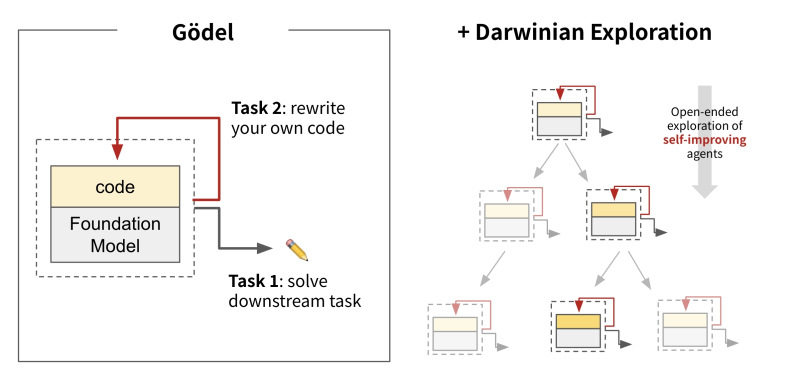
Принцип работы машины Дарвина–Гёделя: слева — отдельный гёделевский «цифровой организм»; справа — группа таких «организмов», участвующих в дарвиновском отборе (источник: Sakana.ai)
С технической точки зрения реализация такой симуляции сводится к нескольким вполне понятным этапам:
- запуск, при котором хаотичным (это критично!) способом формируется набор разнообразных совместимых (для последующего объединения) ИИ-алгоритмов или даже целых готовых моделей;
- проверка посредством тестирования каждой созданной на начальном этапе модели на определённой задаче (например, распознавание образов, управление в видеоигре и т. д.), которая предполагает ясные численные показатели успешности выполнения;
- селекция путём прямого сравнения моделей по числу заработанных на втором этапе очков: модели, показавшие наилучшие результаты, признаются «выжившими» и переходят к следующему этапу;
- вариативность и передача признаков: отобранные модели копируются с добавлением случайных изменений (аналог биологических мутаций) и/или смешиваются (скрещиваются), создавая новое поколение —
- приспособленность которого затем снова оценивается в следующем цикле, полностью повторяющем только что описанный процесс.
На первый взгляд, это действительно кажется простым — однако именно такие повторяющиеся итерации, которые в итоге привели к появлению на Земле существ с достаточно сложным интеллектом, биологическим формам жизни пришлось осуществлять примерно 4,1 миллиарда лет подряд. Хочется надеяться, что в цифровом пространстве компьютерной памяти нейроэволюция будет развиваться куда более впечатляющими темпами, тем более что она начинается не с цифровых копий каких-нибудь архей или вирусов, а сразу с контура, имитирующего достаточно сложные мыслительные процессы.

Динамическое представление работы машины Дарвина–Гёделя — саморазвивающегося программиста-агента, который модифицирует свой собственный код для улучшения эффективности выполнения поставленных задач. Этот агент создаёт дочерние версии (child), внедряя в них как позитивные изменения, так и историю предыдущих модификаций, включая причины отказа от неудачных нововведений (источник: Sakana.ai)
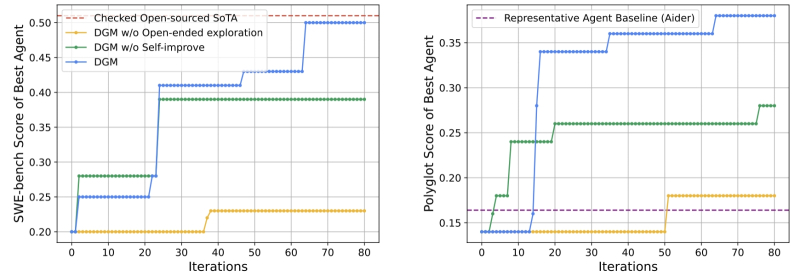
Какова вообще цель машинной нейроэволюции — ведь материальные издержки на конкурентоспособное развитие множества моделей с сопоставимыми аппаратными требованиями, вероятно, окажутся огромными? Ответ кроется в той самой изменчивости под влиянием внешней среды, которую обеспечивает дарвиновский принцип. Подавляющее большинство современных больших языковых моделей (БЯМ) остаются статичными и после завершения обучения не способны к самостоятельному самосовершенствованию без вмешательства человека. Агентные системы частично решают эту проблему, однако в их основе всё равно лежат те же большие модели с фиксированными весами. Именно поэтому агенты (несмотря на всю их очевидную гибкость, включая возможность быстрого дообучения на ходу) продолжают испытывать проблемы с галлюцинациями, «забывчивостью» при смене сессий и накоплением стохастических ошибок, которые часто распространяются по многоэтапным рабочим процессам. Исследователи, работающие в этой области, склонны рассматривать ИИ-агенты скорее как надстройки для автоматизации, которые не способны компенсировать врождённые недостатки лежащей в их основе БЯМ, а не как по-настоящему эволюционирующие, адекватно обучаемые (и, что важно, закрепляющие доказавшие свою полезность новшества в своей структуре) нейросети.
Действительно революционным достижением в данной сфере может стать недавно предложенная, весной 2025 года, машина Дарвина–Гёделя, в названии которой увековечены как «отец теории эволюции» Чарльз Дарвин, так и Курт Фридрих Гёдель, создатель знаменитой теоремы о неполноте, которого Эйнштейн назвал «величайшим логиком со времён Аристотеля». Напомним, что главный недостаток современных БЯМ — их неспособность изменять собственную структуру. Речь идёт не о корректировке отдельных весов, а о перестройке самих перцептронных слоёв и других рабочих элементов нейросети — хотя технических препятствий для этого практически нет, ведь сеть в любом случае эмулируется в памяти сервера (или более простого компьютера, если речь о малых языковых моделях). Перспективный саморазвивающийся ИИ должен быть избавлен от этого ограничения, умея улучшать собственную архитектуру и адаптироваться для эффективного решения всё более сложных задач — точно так же, как живые организмы поколение за поколением приспосабливаются к более успешному развитию (а точнее, к более эффективной передаче генетического кода, пусть и с изменениями, следующим поколениям) в своей среде обитания.
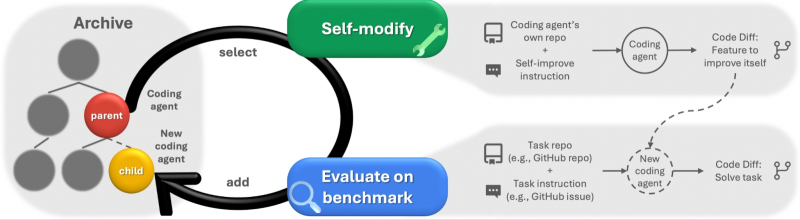
Машина Дарвина–Гёделя итеративно формирует растущий архив агентов, используя принципы недетерминированного поиска (open-ended exploration). Новые агенты создаются и оцениваются не исходя из каких-то предварительных предположений о конкретном направлении их совершенствования, но путём чередования самомодификации с последующей оценкой результатов (источник: Sakana.ai)
⇡#Настала пора задуматься
Ладно; ясно, зачем здесь Дарвин. Но при чём тут Гёдель? Всё дело в том, что помимо биологической эволюции существует ещё один исключительно продуктивный механизм формирования невероятно сложных структур — причём нематериальных, напрямую связанных с нейросетями, которые моделируются в компьютерной памяти. Речь идёт о научном способе познания мира. Его история, правда, короче дарвиновской эволюции (принято считать, что зародился он в Древней Греции, в VI–IV веках до нашей эры), однако эффективность его просто колоссальна. Если с биологической точки зрения современный человек почти не отличается от кроманьонца, который пришёл в Европу 40–45 тысяч лет назад, то в плане образа жизни различия между этими двумя представителями одного вида Homo sapiens колоссальны — благодаря стремительным темпам социальной эволюции, а в последние 2–3 тысячи лет — ещё и открытию того самого научного метода, а затем его успешному применению.
В научной сфере прогресс — накопление и развитие объективно проверяемого понимания природных явлений и процессов — осуществляется через выдвижение гипотез, их последующую проверку и применение предсказательной силы полученных теорий (которые, по сути, переходят на новый уровень благодаря практическому подтверждению гипотез) для дальнейшего продвижения. Параллельно с этим эволюция — снова вспоминаем Дарвина — улучшает биологические организмы (точнее, биологические виды; не случайно в названии основного труда этого учёного речь идёт о происхождении видов, а не отдельных существ) через изменчивость и отбор. Идея Дженни Чжан (Jenny Zhang) и её коллег из Университета Британской Колумбии и стартапа Sakana.ai, представленная в работе «Машина Дарвина–Гёделя: открытая эволюция самосовершенствующихся агентов», заключается именно в создании такого ИИ, который сможет динамически изменять (переписывать, да — ведь генерировать программный код БЯМ уже умеют если не отлично, то очень хорошо) свою собственную структуру, испытывать её на реальных задачах — а затем тщательно дорабатывать собственный программный код. При этом стремясь к максимально возможному устранению пятнающих светлый образ современных БЯМ недостатков: галлюцинаций, уязвимости к обманным техникам (adversarial attacks) и прочих крайне досадных несовершенств. Несовершенства существуют и в живой природе, это верно — но именно в этом проявляется очищающая сила дарвиновского отбора: от поколения к поколению выживают всё лучше приспособленные к своей среде организмы. ИИ с аналогичной динамикой развития в полной мере заслужит название саморазвивающегося.