Китайский разработчик DeepSeek представил предварительное издание большой языковой модели V4. Выпуск состоялся спустя более года после презентации модели R1 с поддержкой рассуждений, которая вызвала резонанс на мировых технологических рынках благодаря выдающейся эффективности и низкой стоимости. Примечательно, что анонс DeepSeek V4 произошёл всего через несколько часов после презентации OpenAI GPT-5.5.

Источник изображения: AI
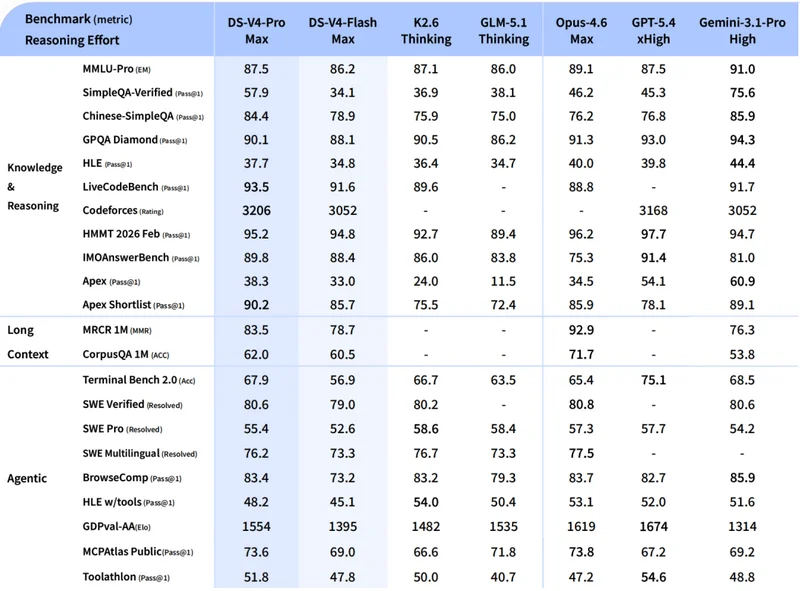
Как и предшествующая модель DeepSeek V3, новая версия алгоритма обладает открытым исходным кодом, что даёт разработчикам возможность разворачивать нейросеть локально и вносить в неё изменения по своему усмотрению. Компания DeepSeek утверждает, что V4 показывает высокую производительность по сравнению с китайскими аналогами, особенно в агентных сценариях, обработке информации и логических умозаключениях. Кроме того, DeepSeek V4 адаптирована для работы с популярными ИИ-агентами, включая OpenClaw и Anthropic Claude Code. Доступны версии «pro» и «flash», которые различаются по объёму и производительности. DeepSeek-V4-Pro насчитывает 1,6 триллиона параметров (49 миллиардов активных) и обладает производительностью, «сравнимой с лучшими закрытыми моделями в мире». DeepSeek-V4-Flash содержит лишь 284 миллиарда параметров, из которых 13 миллиардов активны.

Версия Pro опережает все существующие открытые модели в области математики и программирования, а также способна конкурировать в этих сферах даже с лучшими закрытыми аналогами. При этом знания модели о мире «уступают только Gemini 3.1 Pro». Версия Flash, в свою очередь, предоставляет возможности рассуждения, близкие к уровню V4-Pro, и справляется с простыми задачами в агентном режиме на уровне V4-Pro.
Компания DeepSeek была основана в 2023 году, а внимание к себе привлекла в 2024-м, выпустив бесплатную ИИ-модель V3 с открытым исходным кодом. Этот алгоритм оказался экономически выгодным, так как на его создание было потрачено значительно меньше средств по сравнению с западными конкурентами, например, от OpenAI и Google.
В январе 2025 года компания DeepSeek представила модель R1, которая продемонстрировала результаты на уровне или выше многих конкурентов. Эта модель вызвала беспокойство среди инвесторов после того, как DeepSeek сообщила, что на её разработку с использованием не самых мощных ускорителей Nvidia ушло всего два месяца и менее 6 миллионов долларов. Это поставило под сомнение лидерство США в области искусственного интеллекта, а также огромные затраты технологических компаний на ИИ-инфраструктуру.
По мнению аналитика MorningStar Айвена Су (Ivan Su), алгоритм V4 вряд ли окажет на отрасль такое же воздействие, как R1, поскольку рынки уже осознали, что китайский ИИ является конкурентоспособным и более дешёвым в эксплуатации. Он также отметил, что новая позиция DeepSeek делает другие китайские модели ИИ с открытым исходным кодом прямыми соперниками. «Такой формулировки не было во времена R1, и это уже свидетельствует о том, насколько возросла внутренняя конкуренция», — добавил Су.
Ключевой вопрос после запуска DeepSeek V4 заключается в том, какие ускорители применялись для обучения модели. На этой неделе китайский технологический гигант Huawei подтвердил, что его новейший вычислительный ИИ-кластер на базе ускорителей Ascend способен поддерживать модель DeepSeek V4. Однако остаётся неясным, в какой степени ускорители Huawei использовались для обучения новой ИИ-модели.
Новые модели DeepSeek уже доступны в веб-версии и приложении чат-бота DeepSeek, где режим Instant основан на V4-Flash, а Expert — на V4-Pro. Разработчики также получили доступ к новинкам через API.




