По целому ряду причин — таких как импортозамещение, предписания регуляторов для объектов КИИ, отсутствие поддержки, ограниченный доступ к платным функциям, вопросы безопасности и другие — многие российские компании вынуждены отказываться от open-source-инструментов.
В 2025 году компания «Лаборатория Числитель» представила платформу для визуализации данных «Графиня» — первое российское решение, аналогичное Grafana. Разработчики поставили перед собой задачу устранить одну из главных проблем Grafana при крупных развертываниях: после обновлений нередко выходили из строя десятки дашбордов. Помимо этого, они хотели предоставить пользователям функционал enterprise-версии Grafana, которая больше недоступна для приобретения в России.
С 2019 года «Лаборатория Числитель» работает над тремя продуктами: «Штурвал» (централизованное управление кластерами Kubernetes), «Нимбиус» (частные и гибридные облака) и «Пульт» (система мониторинга на основе Zabbix). «Графиня» изначально задумывалась как модуль визуализации для «Пульта», однако рыночный интерес оказался столь велик, что разработчики решили выделить её в отдельный продукт с собственной стратегией развития.
«Графиня» включена в Единый реестр российских программ для ЭВМ Минцифры, что делает её законным выбором для организаций, обязанных соблюдать требования импортозамещения. Кроме того, ПО вендора в настоящее время проходит сертификацию ФСТЭК по 4-му уровню доверия.

Главная страница «Графини»
Зачем мониторингу отдельная визуализация
Чтобы понять положение «Графини» на рынке, необходимо разобраться, почему визуализация данных мониторинга в принципе заслуживает статуса самостоятельного продукта. Система мониторинга выполняет широкий круг задач: сбор данных, выявление и предотвращение инцидентов, оповещение о них, а также визуализация, формирование отчетов, интеграция и автоматизация. Однако если спросить обычного пользователя мониторинга — не инженера, настраивающего систему, а того, кто ею пользуется, — то окажется, что большинство сталкивается лишь с двумя элементами: оповещениями и визуализацией. Более того, нередко, отвечая на вопрос о наличии системы мониторинга, пользователи упоминают именно Grafana, хотя она обеспечивает только отображение данных, а не весь процесс мониторинга.
При этом разные категории потребителей предъявляют к визуализации принципиально различные требования. Дежурной смене необходимы данные в реальном времени и единое окно, объединяющее информацию из нескольких систем. Службе эксплуатации нужны фильтры, выборки и глубокая детализация — возможность «погрузиться» от уровня сервиса до состояния конкретного интерфейса или процессора. Разработчикам и DevOps-инженерам важна скорость развертывания, чтобы быстро создать визуализацию, проверить гипотезу и двигаться дальше. Руководителям и владельцам информационных систем требуется агрегация данных за длительные периоды, аналитика и кастомизация с изоляцией данных. А бизнес зачастую просто хочет, чтобы «все было красиво и хорошо», — и в каждой новой компании представление о красоте оказывается своим.
Встроенная визуализация систем мониторинга обычно покрывает не более трети этих потребностей, а некоторые системы и вовсе лишены визуальной составляющей. Именно эту нишу в свое время заняла Grafana, ставшая де-факто стандартом визуализации в мониторинге, — и теперь этот пробел призвана восполнить «Графиня» в условиях импортозамещения.
Написано с нуля
Разработчики сознательно отказались от создания форка Grafana и написали «Графиню» полностью с нуля. Прямых конкурентов в этом сегменте среди российских решений сейчас нет. Компании, привыкшие работать с Grafana, получают возможность перейти на инструмент, знакомый по концепции, но полностью российский.
Стоит отметить, что на мировом рынке формируется альтернативное направление: проект Perses, развиваемый под эгидой фонда CNCF при участии Red Hat, предлагает cloud-native-подход к визуализации данных мониторинга. Perses существует с 2022 года и нацелен на преодоление архитектурных ограничений Grafana, прежде всего ее монолитности. Однако для российского рынка, где ключевым требованием является присутствие в реестре отечественного ПО и наличие локальной поддержки, Perses не может рассматриваться как альтернатива «Графине».
Не менее важно разграничить «Графиню» и BI-решения. Внешне класс BI-продуктов — например, Superset, Redash, Tableau и их аналоги — выполняет похожие функции: они подсоединяются к источникам информации и формируют визуальные отчеты. Однако BI-системы нацелены на бизнес-аналитику и оперируют крупными объемами накопленных данных, тогда как Grafana и «Графиня» берут начало из задач оперативного мониторинга в реальном времени, где ценятся интерактивность, быстрое создание панелей и автоматизация через концепцию «инфраструктура как код» (IaaC). Развернуть «Графиню», присоединить источник информации и сделать первый рабочий дашборд можно буквально за пять минут — лишь немногие BI-системы могут предложить сопоставимую скорость запуска.
Архитектура и взаимодействие с плагинами
Подход с акцентом на бэкенд
Главное архитектурное различие между «Графиней» и Grafana лежит в методе работы с плагинами источников информации. В Grafana каждый плагин содержит как фронтенд, так и бэкенд, причем фронтенд-часть обязательно пишется на React с применением собственных библиотек Grafana. Это заметно увеличивает порог вхождения для создателей плагинов.
В «Графине» подход совершенно другой. Плагины реализованы как бэкенд-компоненты. Для разработки нового плагина достаточно придерживаться REST API, а сам плагин можно написать на любом удобном языке программирования. Такая схема существенно упрощает создание новых интеграций и расширяет круг специалистов, способных разрабатывать плагины для этой платформы.
Развертывание плагинов базируется на контейнерной архитектуре. Чтобы подключить новый плагин, нужно лишь добавить соответствующий контейнер в docker-compose, а затем в интерфейсе пользователя указать ссылку на контейнер через HTTP(S). После этого настройка источника информации выполняется через стандартные поля конфигурации. При этом плагины автоматически генерируют формы настройки на основе контрактов — внутреннего API, который описывает параметры подключения, что гарантирует единообразие конфигурационного интерфейса для всех источников информации.
Контейнерная модель не ограничивается только локальным запуском рядом с основным приложением. Плагины могут разворачиваться как отдельные контейнеры на выделенных серверах и подключаться к «Графине» через API. Это дает возможность распределять интеграционные компоненты по инфраструктуре, выносить наиболее загруженные подключения на отдельные узлы и масштабировать их независимо от основного приложения.
Хранение информации и принцип работы в реальном времени
Как и Grafana, «Графиня» не хранит данные мониторинга. Конфигурация — пользователи, дашборды в формате JSON и параметры подключения — сохраняется в MongoDB. Сами же данные запрашиваются из источников на лету: бэкенд обращается к плагинам, получает нужную информацию и передает ее на фронтенд для отображения. Такой подход означает, что платформа не дублирует хранилища информации и не создает избыточной нагрузки на дисковую подсистему.
Многоуровневое кеширование
Специалистами была внедрена многоуровневая система кеширования запросов. Если в Grafana каждый запрос отправляется напрямую в плагин, то в «Графине» все обращения сначала поступают на бэкенд, который группирует их и направляет пачками к соответствующим плагинам. Особого внимания заслуживает механизм дедупликации на уровне плагинов. Когда на одной витрине данных несколько виджетов запрашивают одинаковую или частично пересекающуюся информацию из одного источника, плагин «Графини» объединяет эти вызовы в единый запрос, тогда как Grafana обрабатывает каждый из них по отдельности.
На практике это обеспечивает заметный прирост производительности: во время разработки первого плагина для «Пульта» / Zabbix аналогичный дашборд в Grafana вызывал зависание браузера, в то время как «Графиня» успешно обрабатывала все данные, сохраняя отзывчивость интерфейса. Дополнительный вклад вносит и то, что в ряде случаев плагин не запрашивает повторно весь временной промежуток, если часть сведений уже была получена ранее, а догружает лишь недостающие данные. Это ещё больше снижает нагрузку на источник при повторных и пересекающихся запросах.
В будущих обновлениях планируется расширить систему кеширования за счёт интеграции с самими дашбордами. Речь идёт о фоновом предрасчёте тяжёлых витрин по расписанию, чтобы при открытии пользователь сразу получал готовые данные, не дожидаясь повторного выполнения всех запросов. Такой подход должен ускорить работу сложных отчётов и уменьшить нагрузку на внешние системы в ситуациях, когда одной витриной одновременно пользуется множество сотрудников.
Безопасность на уровне архитектуры
Архитектура, ориентированная на бэкенд, предоставляет ещё одно значительное преимущество в области информационной безопасности. Пользователи могут настроить разграничение доступа таким образом, что к закрытому источнику данных будет обращаться только плагин, а пользовательский интерфейс не будет иметь прямого доступа к этому источнику. Связь между плагином и бэкендом при этом настраивается отдельно. Такая схема добавляет дополнительный уровень защиты при работе с конфиденциальными данными.
Развёртывание и инсталляция
Установка «Графини» производится полностью в Docker-контейнерах и подробно описана в документации на портале продукта. Для запуска достаточно создать папку, поместить в неё три конфигурационных файла (docker-compose и два файла настроек), подключиться к реестру контейнеров и выполнить команду docker-compose up. По умолчанию платформа запускается на 80-м порту, однако порт легко изменить в конфигурации. Весь процесс — от загрузки контейнеров до открытия интерфейса в браузере — занимает всего несколько минут.
Для получения доступа к реестру контейнеров «Лаборатории Числитель» необходимо связаться с разработчиками — на данный момент выдаются индивидуальные учётные данные, что позволяет контролировать распространение продукта на этапе раннего внедрения.
В ближайших планах значится интеграция с платформой «Штурвал» (Kubernetes-решение от «Лаборатории Числитель»), что даст возможность развёртывать и масштабировать «Графиню» в среде Kubernetes-кластеров. На данный момент основным подходом остаётся классическое развёртывание в Docker, однако архитектура продукта не содержит серьёзных ограничений для работы в оркестрированных контейнерных средах. Система изначально спроектирована с учётом горизонтального масштабирования отдельных компонентов, таких как плагины и проксирующие узлы, а для развёртывания в Kubernetes уже подготовлены Helm-чарты. При этом команда пока не обнародовала официально подтверждённые лимиты по количеству пользователей, числу источников данных или объёму событийной нагрузки: специализированные нагрузочные тесты ещё не преобразованы в публичные характеристики.
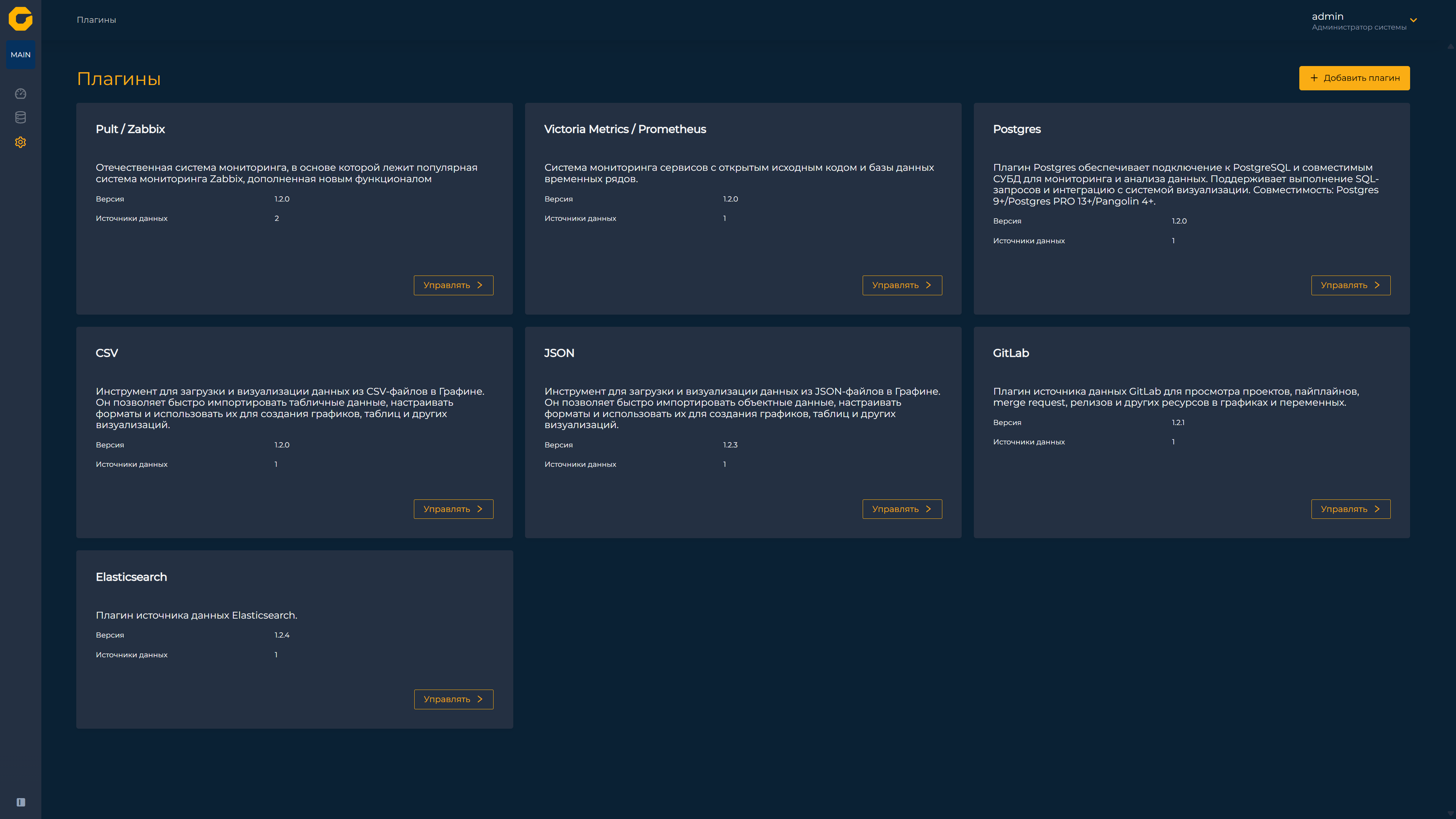
Источники данных
На сегодняшний день «Графиня» умеет работать с несколькими типами источников данных. В первую очередь это «Пульт» и Zabbix, для которых создан единый плагин, учитывающий, что первый построен на основе второго и обогащён собственными возможностями. Плагин собирает данные через API и поддерживает как «сырые» данные (история), так и тренды. В Zabbix и «Пульте» «сырые» данные хранятся ограниченное время, например неделю, после чего преобразуются в тренды, содержащие агрегированные показатели (среднее, минимальное, максимальное) за полчаса или час. Плагин позволяет настроить порог временного диапазона, при котором запрос переключается с «сырых» данных на тренды, а также задать время кеширования для уменьшения нагрузки на источник.
Из «Пульта» и Zabbix можно получать несколько типов данных: метрики, текст, триггеры, проблемы и состояние сервиса. Для метрик реализован конструктор с выпадающими списками. Пользователь выбирает группу хостов, затем конкретный хост, затем нужную метрику — и данные отображаются в виджете. Поддерживаются регулярные выражения в полях выбора: можно указать маску вместо конкретного хоста, и все подходящие объекты будут динамически подтягиваться в визуализацию. Это особенно удобно при масштабировании инфраструктуры, так как новые объекты, соответствующие регулярному выражению, автоматически появляются на витрине данных без дополнительной настройки.
Также реализована поддержка Victoria Metrics и Prometheus, что позволяет подключать системы мониторинга сервисов и базы данных временных рядов. Для запросов к этим источникам используется язык PromQL (Prometheus Query Language), который указывается в настройках подключения. Помимо визуального конструктора запросов, поддерживается режим написания кода, где пользователь может вручную составлять PromQL-выражения. Администратор имеет возможность запретить режим кода для конкретного источника данных, если этого требуют политики безопасности или эксплуатации.
Перечень расширений
Для взаимодействия с реляционными базами данных разработан модуль PostgreSQL, который поддерживает версии PostgreSQL от 9 и выше, Postgres Pro от 13 и выше, а также СУБД Pangolin DB от версии 4 и выше. В режиме написания кода доступен полноценный SQL, включая сложные запросы с объединениями таблиц и условиями отбора. Чтобы избежать избыточного извлечения данных, предусмотрен настраиваемый лимит записей на уровне источника. Администратор может установить максимальное число возвращаемых строк или отключить ограничение, указав значение «0».
Кроме того, система поддерживает универсальные форматы — JSON и CSV. Работа с ними организована с высокой гибкостью. Можно загрузить файл напрямую, указать ссылку на динамический справочник по HTTP или HTTPS (с возможностью настройки сертификатов и проверки подлинности), разместить файл в файловой системе сервера плагина и указать путь, вставить данные прямо в интерфейсе или выбрать файл через окно загрузки. При загрузке через интерфейс файл кодируется и сохраняется внутри системы. Разделитель полей в CSV также можно настроить. В последнем обновлении добавились модули для GitLab API, Elasticsearch и СУБД ClickHouse.
Для каждого источника данных предусмотрено несколько режимов настройки запросов: визуальный конструктор, режим написания кода и работа через JSON. Конструктор подходит для пользователей, которые не хотят изучать синтаксис запросов — достаточно заполнить выпадающие списки и параметры, чтобы получить данные. Режим кода предназначен для опытных пользователей и позволяет, например, составить произвольный SQL-запрос для PostgreSQL или PromQL-запрос для Prometheus и Victoria Metrics. Разработчики планируют добавить подсказки и автозаполнение в режиме кода, что ускорит написание запросов и уменьшит количество ошибок — по аналогии с тем, как это сделано в Grafana при работе с Prometheus и Victoria Metrics. Также планируется постепенно расширять список поддерживаемых модулей, начиная с самых востребованных интеграций и увеличивая их количество на основе отзывов пользователей.
Отображение данных
Дашборды и элементы
Основным элементом интерфейса «Графини» являются витрины данных (аналоги дашбордов). Каждая витрина объединяет информацию из разных источников в едином пространстве. При создании витрины указываются название, описание, теги и частота автоматического обновления данных. Разработчики реализовали полный базовый набор типов визуализации, включающий графики временных рядов, круговые диаграммы, индикаторы в стиле спидометра, табличное представление данных и другие виды отображения.
Инструмент для настройки виджета состоит из трёх основных блоков: панели предварительного просмотра, раздела конфигурации запросов к источникам данных и зоны управления визуальным оформлением. В блоке параметров отображения предусмотрены переопределения — функция, позволяющая для каждого столбца таблицы или линии на графике устанавливать индивидуальные характеристики: единицы измерения (байты, проценты, секунды), формат показа, цветовую гамму и другие настройки. Это особенно удобно при работе с таблицами, где разные колонки могут требовать собственного стиля представления.
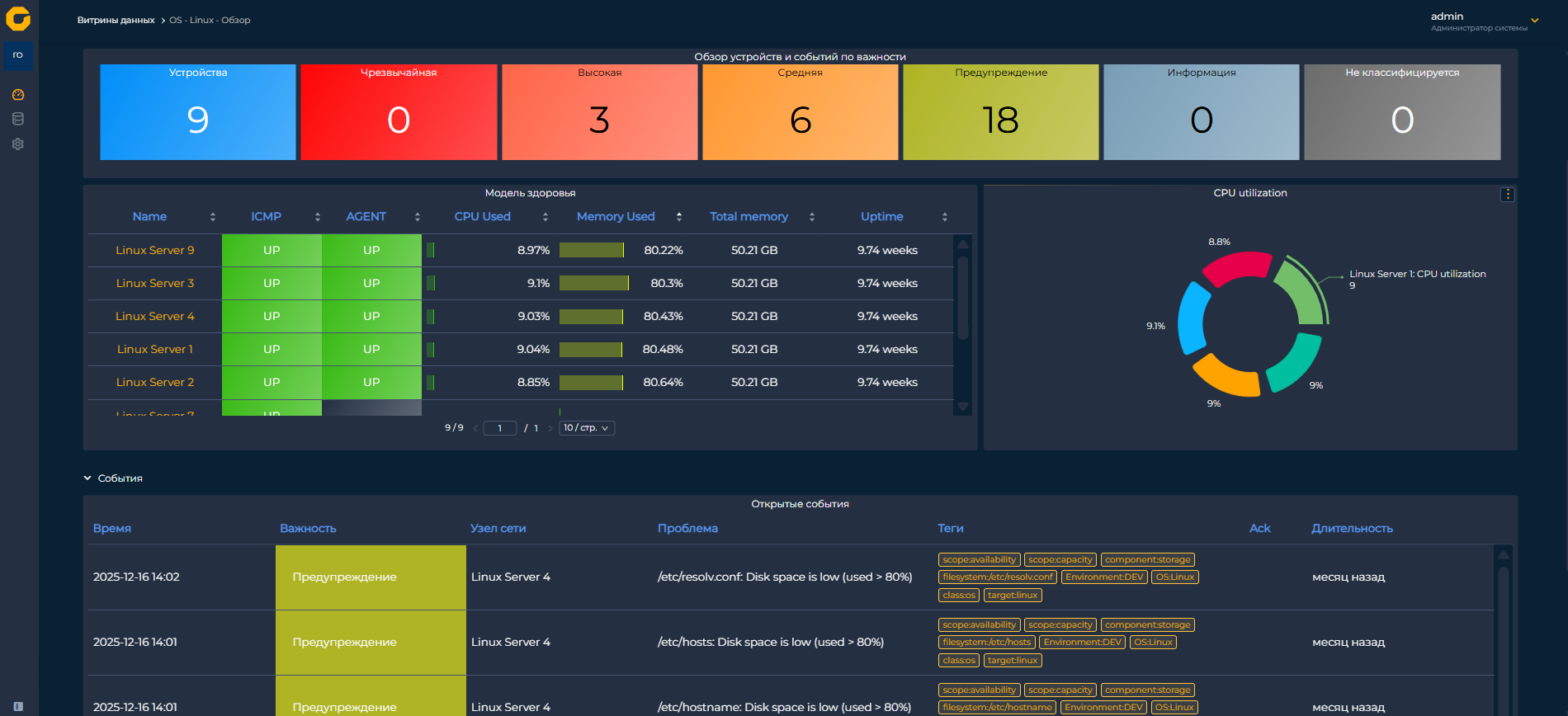
Режим просмотра
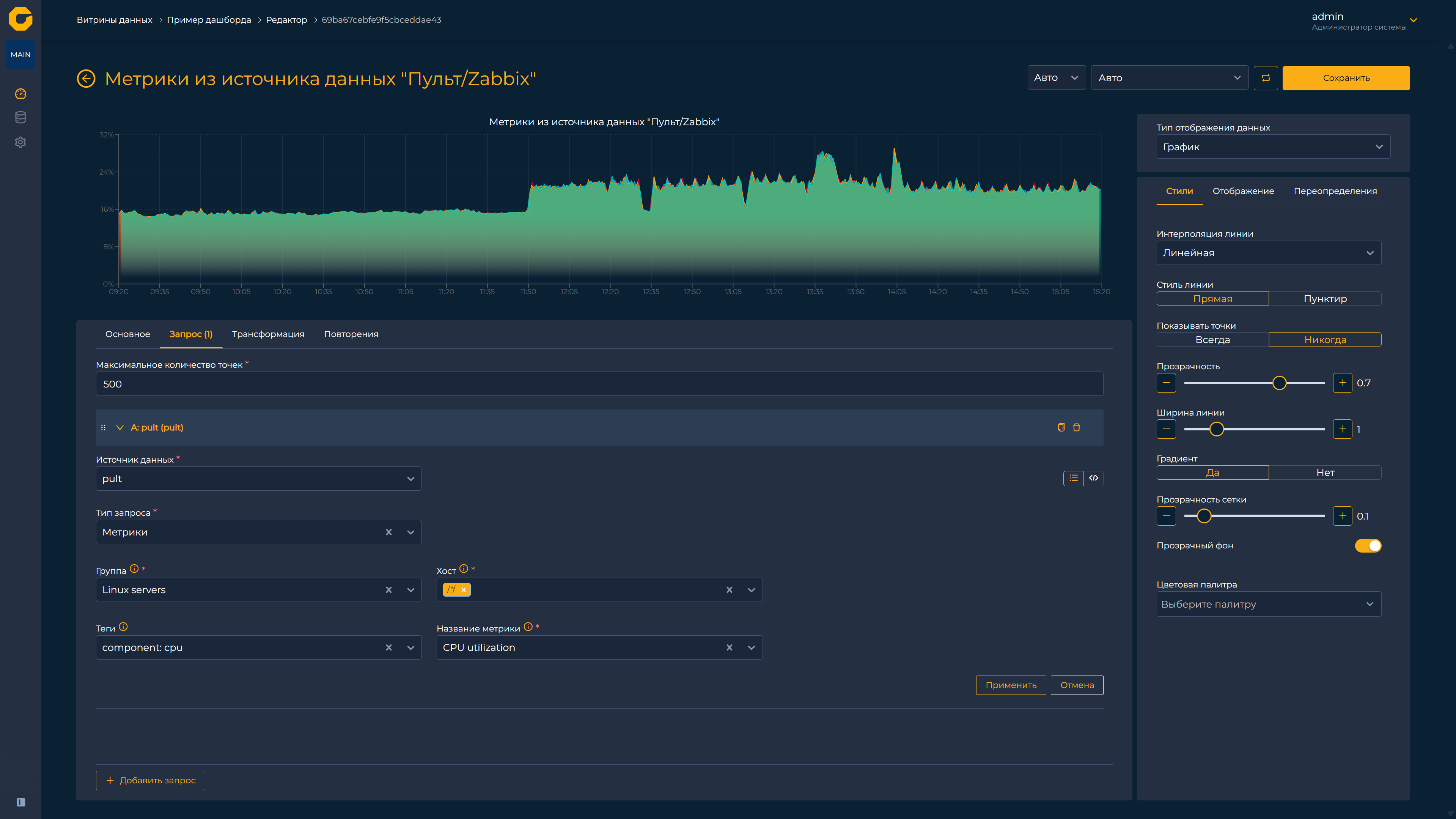
Режим редактирования
Для упрощения процесса создания однотипных виджетов добавлена опция копирования. Любой виджет можно продублировать одним нажатием, после чего скорректировать тип визуализации или параметры запроса. Это существенно ускоряет заполнение информационной панели.
Отдельного внимания заслуживают специализированные виджеты. Например, для системы «Пульт» разработана «Модель здоровья» — предварительно настроенная таблица с расширенными параметрами, позволяющая в одном окне отслеживать состояние множества контролируемых узлов, доступность по ICMP и через агента, загрузку процессора и памяти, время работы и другие важные показатели. Виджет «Проблемы» предназначен для вывода текущих событий из системы мониторинга — это ключевой элемент для дежурных смен, где индикаторы могут менять цвет и мигать при возникновении инцидентов.
Платформа поддерживает отображение данных в реальном времени с настраиваемой периодичностью обновления, что позволяет выводить информационные панели на экраны в дежурных комнатах. Для этого, в частности, предусмотрены плейлисты — последовательная демонстрация панелей по заданному расписанию с автоматическим обновлением. Также доступен киоск-режим, который убирает из интерфейса лишние элементы и делает «Графиню» удобной для вывода на отдельные мониторы и экраны ситуационных центров.
Реализована работа с переменными и трансформация данных (эта функция находится в стадии активной разработки). Кроме того, в платформе предусмотрены контекстные переходы (drill-down) — от общего обзора к конкретным метрикам.
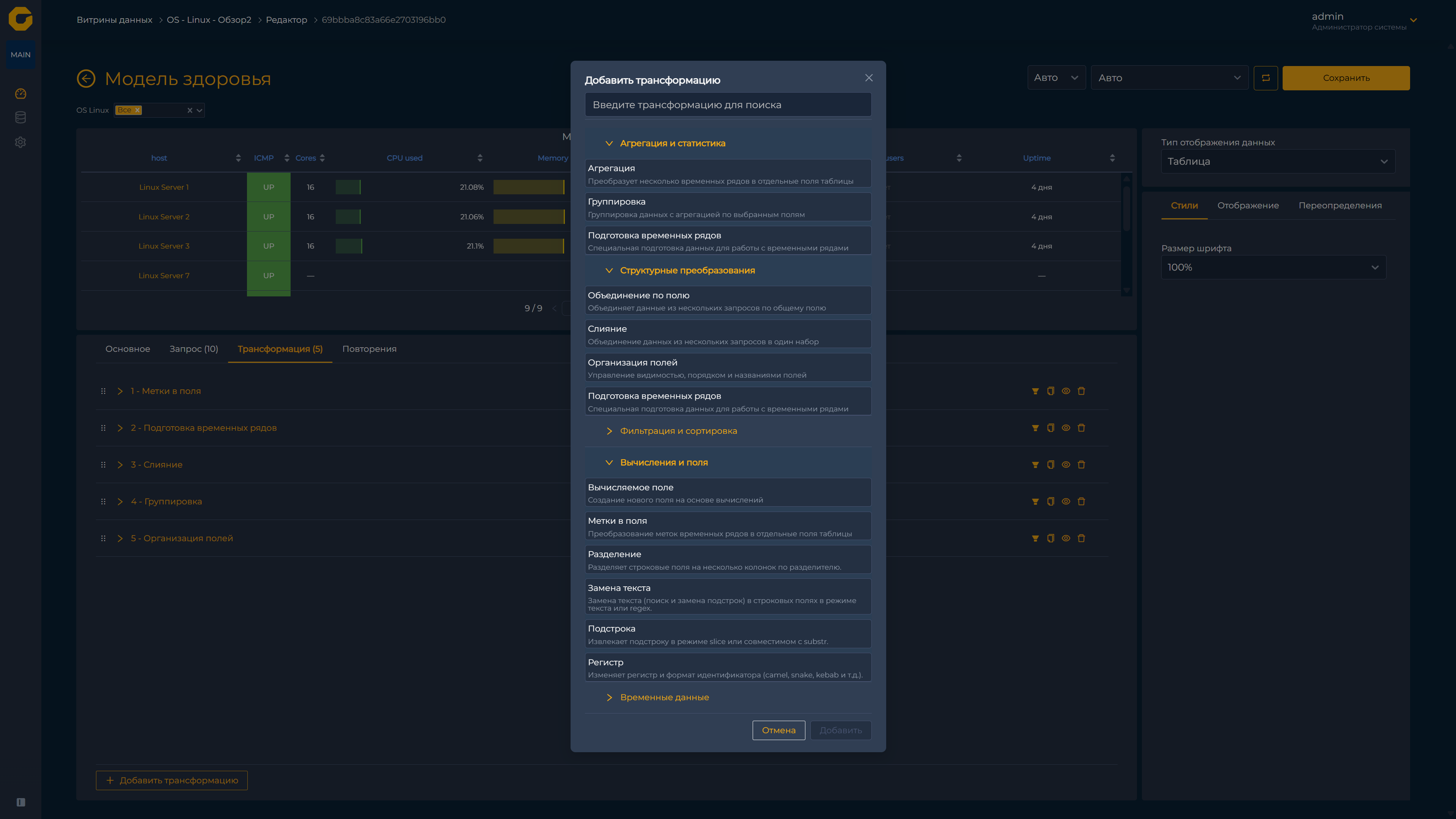
Трансформации
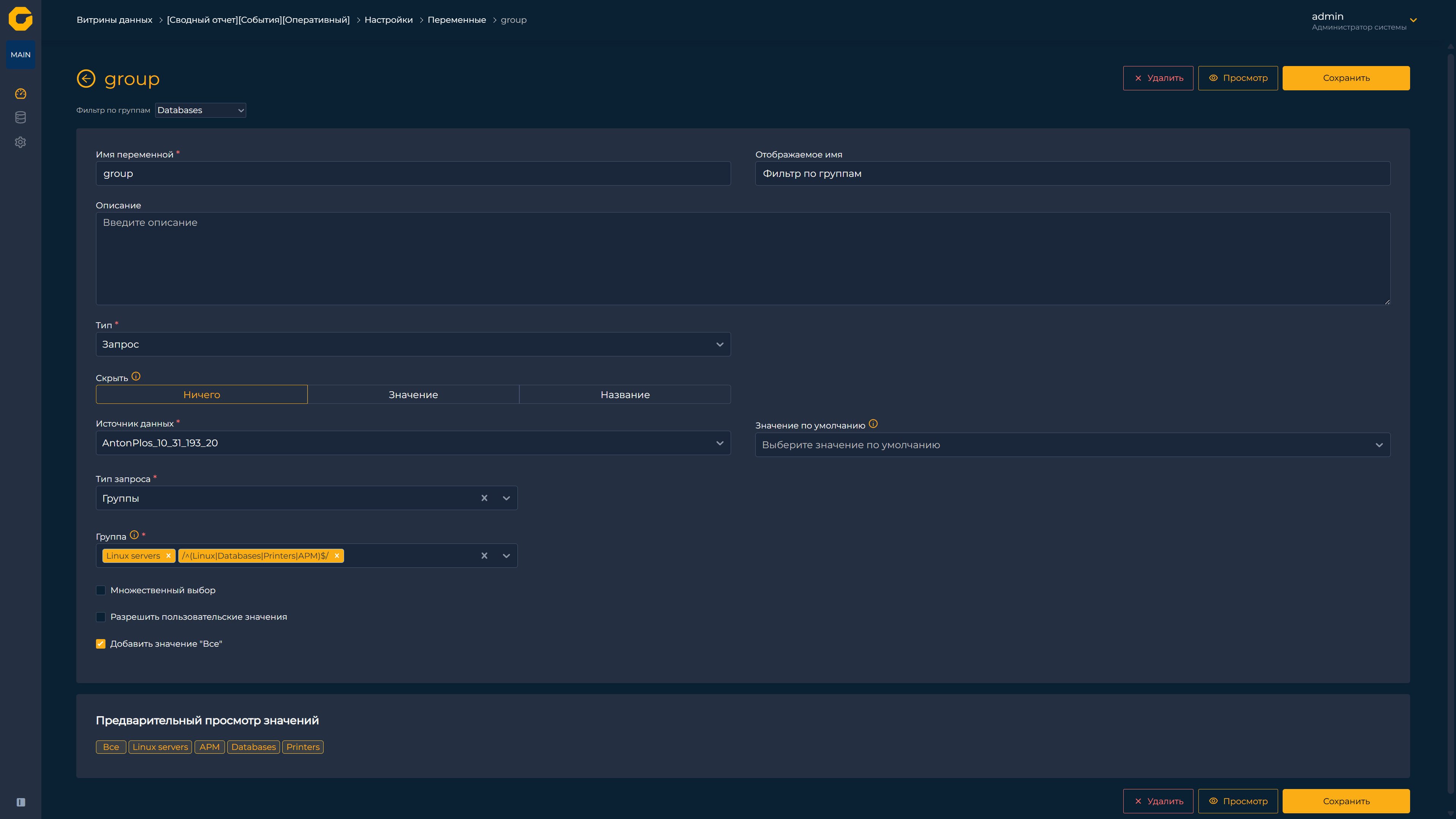
Переменные
Разработчики поясняют эту концепцию как «правило пирога» при формировании панелей мониторинга: верхний ярус демонстрирует состояние ИТ-систем, средний — сводные метрики, а нижний представляет собой подробную карточку, где доступна информация вплоть до отдельного интерфейса или компонента.
Структура витрины: строки и блоки
Для упорядочивания данных на витрине внедрён механизм строк (rows) — сворачиваемых секций, объединяющих набор виджетов. Когда блок свёрнут, запросы к источникам данных для всех виджетов внутри него приостанавливаются, что заметно повышает производительность на сложных витринах с большим количеством элементов. Пользователь видит в верхней части самую значимую информацию в развёрнутом виде, а при необходимости раскрывает дополнительные блоки, загружая данные по запросу. Виджеты можно переносить между строками. В следующих обновлениях планируется внедрить перетаскивание виджетов с помощью drag-and-drop, а также шаблонизацию строк (templating) — автоматическое копирование блока для каждого значения переменной, например для каждого сетевого интерфейса сервера. Иерархия папок в витринах стала доступна в версии 2026H1.
Владельцы витрин данных
В отличие от Grafana, в «Графине» реализована модель владельцев витрин данных. Каждая витрина имеет владельца — пользователя, который её создал. По умолчанию пользователи с правами на редактирование могут изменять только свои собственные витрины. Чтобы работать с чужой витриной, её можно клонировать и затем редактировать копию. Такой подход минимизирует риск случайного повреждения витрин, созданных коллегами. В планах разработчиков — ввести роль «продвинутого пользователя», который сможет редактировать любые витрины в организации, а также механизм передачи прав владения при удалении или деактивации пользователя.
Список дашбордов с указанием ответственных
Экспорт информации
Система позволяет выгружать информацию из виджетов в CSV-формат, а также использовать фильтрацию и переходы между различными панелями.
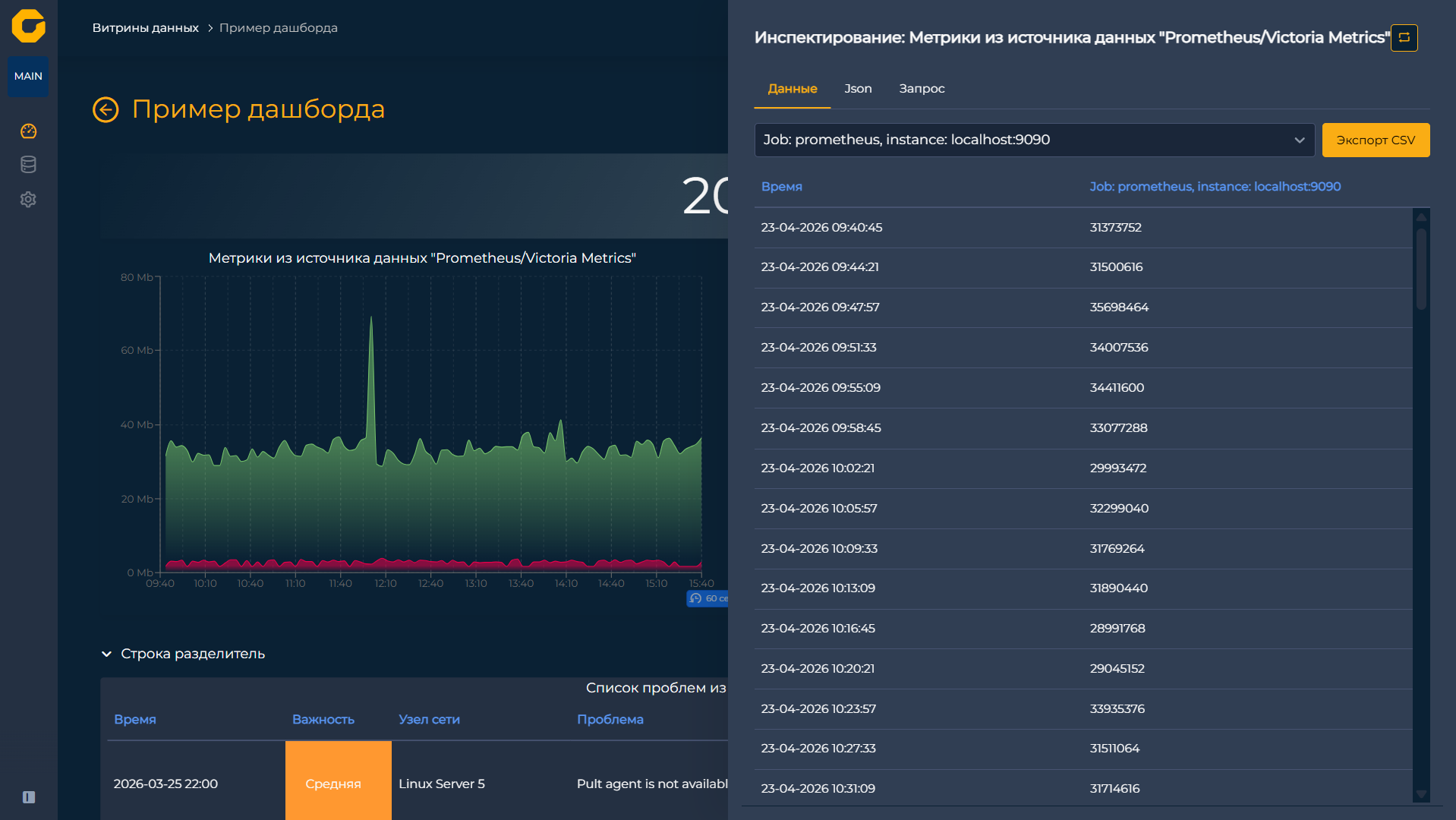
Выгрузка в CSV
Ресурсно-сервисная модель
Особого внимания заслуживает модуль ресурсно-сервисной модели (РСМ). Это не обычный виджет, а полнофункциональный интерактивный блок, который помогает оперативно оценивать состояние ИТ-сервисов в системах Zabbix или «Пульт». Модуль строит древовидный граф, отображающий все объекты и их связи. Кликая на любой элемент графа, пользователь активирует заранее заданные сценарии, которые обновляют данные в соседних виджетах панели. Наглядность сложных взаимосвязей и высокая интерактивность делают этот инструмент незаменимым для быстрого реагирования на инциденты и анализа зависимостей между элементами инфраструктуры.
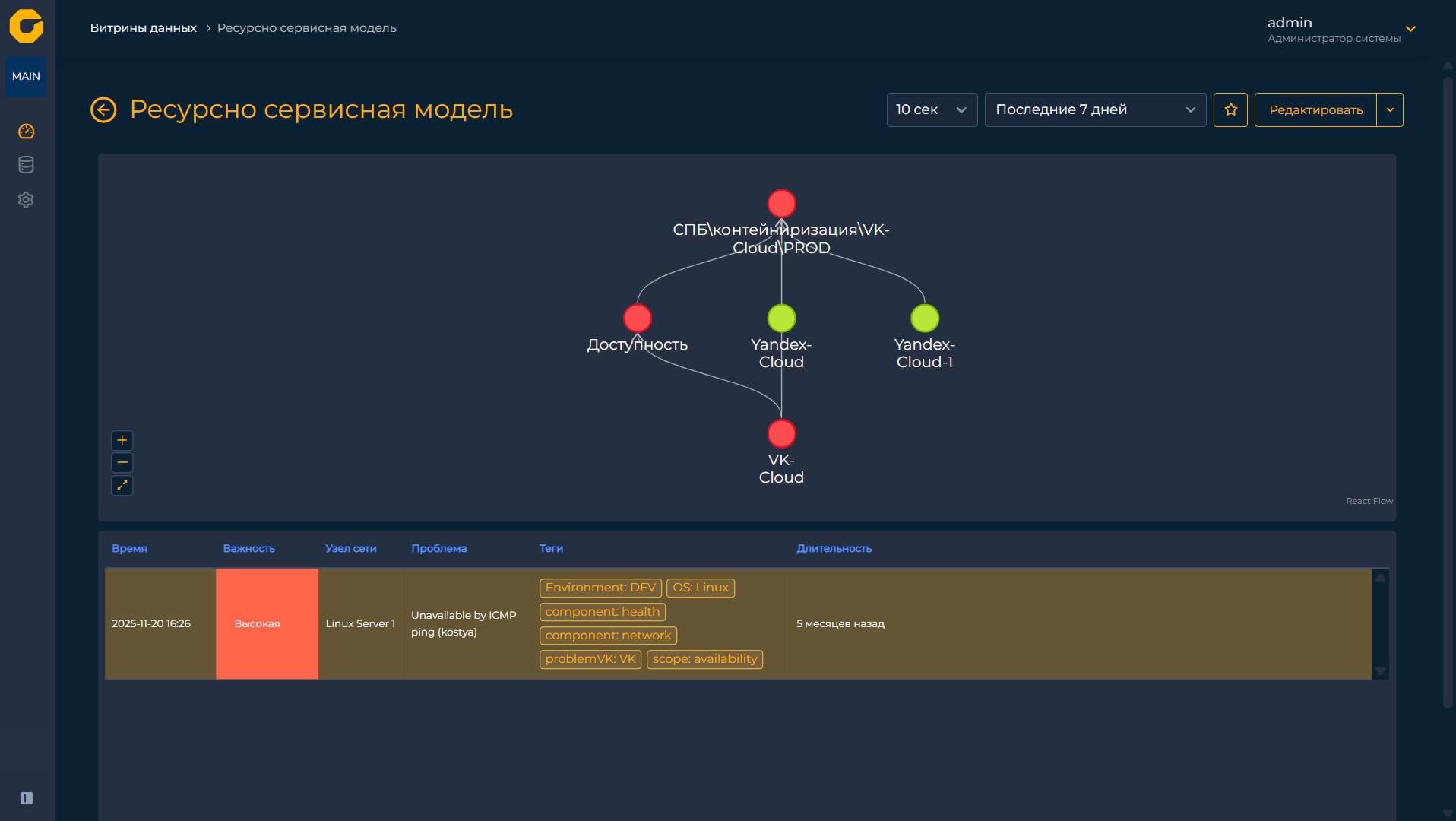
Модуль ресурсно-сервисной модели (РСМ)