SambaNova анонсировала ИИ-ускорители пятого поколения SN50, созданные на базе собственных RDU (Reconfigurable Dataflow Unit). По утверждению разработчика, эти чипы «предлагают уникальное сочетание минимальной задержки, высокой пропускной способности и энергоэффективности для задач ИИ-инференса, кардинально меняя экономику генерации токенов». Параллельно стало известно об инвестициях и партнёрстве с Intel, которая отказалась от первоначального намерения полностью.
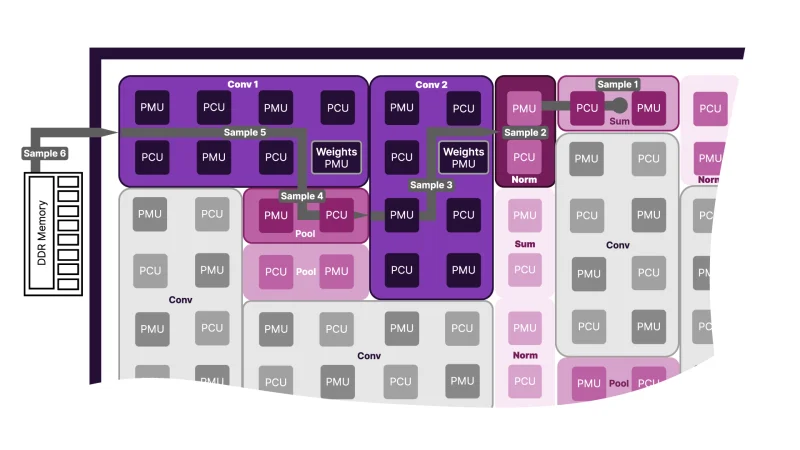
Как сообщает The Register, новый чип демонстрирует существенный прогресс в сравнении с моделью , выпущенной в 2023 году. Согласно данным компании, SN50 обеспечивает прирост производительности в 2,5 раза для 16-битных вычислений (1,6 Пфлопс) и в 5 раз для операций в формате FP8 (3,2 Пфлопс). В основе SN50 лежит потоковая архитектура обработки данных (SambaNova DataFlow). Как и у предыдущего поколения, чип использует трёхуровневую иерархию памяти, объединяющую DDR5, HBM и SRAM, что позволяет системам на его базе работать с ИИ-моделями до 10 трлн параметров и длиной контекста до 10 млн токенов.

Источник изображений: SambaNova
Каждый модуль RDU оснащён 432 МБ SRAM, 64 ГБ памяти HBM2E с пропускной способностью 1,8 ТБ/с, а также объёмом DDR5 от 256 ГБ до 2 ТБ. Наличие HBM2E и гибко настраиваемый объём DDR5 должны повысить привлекательность и доступность решений на SN50 в условиях дефицита памяти. Каждый ускоритель получил интерконнект с пропускной способностью 2,2 ТБ/с (в каждом направлении) для взаимодействия с другими чипами через коммутационную фабрику.
По данным SambaNova, её ускоритель SN50 демонстрирует превосходство над решением , предлагая пятикратное увеличение пиковой скорости генерации токенов на одного пользователя и более чем трёхкратный рост пропускной способности для агентного инференса. Эти показатели были подтверждены тестами с различными моделями, включая Meta✴ Llama 3.3 70B. Конструкция чипа эффективно выгружает KV-кэш и обеспечивает переключение между моделями в памяти HBM и SRAM по принципу «горячей замены» за миллисекунды, что критически важно для агентных задач, где требуется частое переключение между разными ИИ-моделями.
Кроме того, в SN50 реализовано кэширование входных токенов в памяти, что сокращает продолжительность предобработки и уменьшает задержку до выдачи первого токена (TTFT). Подобное сочетание скорости, эффективности и масштабируемости, как заявляет производитель, даёт беспрецедентное преимущество в совокупной стоимости владения (TCO) для провайдеров инференс-сервисов, работающих с такими моделями, как OpenAI GPT-OSS, обеспечивая восьмикратную экономию в сравнении с NVIDIA B200. SN50 также нацелен на приложения вроде голосовых ИИ-помощников, которым необходима сверхнизкая задержка для функционирования в реальном времени. По утверждению компании, система способна обслуживать тысячи параллельных сессий.
Была также анонсирована 20-киловаттная система SambaRack SN50, объединяющая 16 чипов SN50. Такие стойки SambaRack можно масштабировать до кластера из 256 ускорителей с пропускной способностью межсоединений в несколько терабайт в секунду, что ускоряет обработку запросов и позволяет работать с большими пакетами данных. В итоге это открывает возможность развёртывания моделей с повышенной пропускной способностью и отзывчивостью. Поставки ускорителей SN50 клиентам планируется начать во второй половине 2026 года.

Компания SambaNova объявила о в рамках обновлённого раунда финансирования серии E, который возглавила частная инвестиционная фирма Vista Equity Partners при участии Cambium Capital. Как сообщает SiliconANGLE, в раунде также «активно поучаствовало» инвестиционное подразделение Intel — Intel Capital. Параллельно SambaNova рассказала о начале сотрудничества с Intel, направленного на создание высокопроизводительных и экономичных систем для выполнения задач искусственного интеллекта. Их цель — предложить бизнесу альтернативу графическим процессорам, которые в настоящее время доминируют в большинстве рабочих нагрузок.
Инвестиции Intel в стартап призваны ускорить внедрение нового «облачного решения для ИИ», основанного на существующей платформе . Модернизированная платформа, оптимизированная для работы с многомодальными большими языковыми моделями, будет использовать процессоры Xeon, а также графические ускорители, сетевые и другие решения Intel, включая системы хранения данных. Уточняется ли, будут ли создаваться специализированные модели Xeon, как это было , не сообщается. В дальнейшем Intel и SambaNova намерены совместно продвигать и реализовывать новую платформу, задействуя обширные корпоративные связи и партнёрские каналы Intel.

Партнёрство взаимовыгодно для обеих сторон. SambaNova получит доступ к глобальному охвату и производственным мощностям Intel для масштабирования своих ИИ-ускорителей, а Intel, наконец, сможет закрепиться на рынке искусственного интеллекта. До сих пор компании не удавалось составить конкуренцию NVIDIA и другим производителям чипов, таким как AMD, в этой сфере. Совместное использование чипов SN50 от SambaNova и процессоров Intel Xeon потенциально способно изменить текущее положение дел.
Нельзя не упомянуть, что Intel, переживающая , заключила весьма значительное . Помимо этого, корпорация разрабатывает собственные , пусть и гораздо менее сложные, чем SN50, а также создаёт на базе ускорителей Habana и NVIDIA B200. Кроме того, существует по производству и некоторых ускорителей для искусственного интеллекта. Если говорить о других участниках рынка, которые, как и SambaNova, стремятся составить конкуренцию NVIDIA, то компания Groq в конечном итоге этим гигантом, а Cerebras, в свою очередь, заключила с одним из ключевых игроков в сфере ИИ — OpenAI.
Источник: