Представление модели GPT-4o в мае 2024 года стало для её создателя, компании OpenAI, значительным достижением: эта версия авторегрессионного генеративного искусственного интеллекта, в отличие от предыдущих версий, изначально проектировалась как мультимодальная (буква o здесь — сокращение от omni, то есть «универсальный»); с возможностью обработки не только текстов, но и изображений, а также аудиоданных. Именно это позволило версии 4o заметно превзойти во многом архитектурно похожую базовую «четвёрку» в решении соответствующих задач. И распространение авторегрессии на мультимодальные модели явно пришлось по вкусу массовой аудитории: не случайно после неудачного запуска GPT-5 в августе 2025 года — неудачного в том плане, что пользователям ChatGPT сразу перестали предоставлять выбор, с какой моделью взаимодействовать; фактически навязывая новинку, — руководству фирмы пришлось вернуть GPT-4o в настройки платформы, хотя бы и исключительно для подписчиков платных тарифов.
Любопытно, к слову, что всего лишь в апреле того же 2025 года разработчикам пришлось отозвать очередное обновление самой GPT-4o — из-за того, что стиль её общения с пользователями стал излишне угодливым, почти заискивающим. Получается, и излишняя подобострастность генеративной модели раздражает людей, и некоторая холодная отстранённость (пусть и сопровождаемая улучшенным функционалом) вызывает недовольство, — куда же бедному ИИ деваться? А между тем, выдающиеся умения в области мультимодальной генерации и льстивая услужливость при диалоге с пользователем — это две стороны одной авторегрессионной медали. Не зря осенью в OpenAI создали специальное подразделение Model Behavior, задачей которого является формирование социально приемлемых образов (personalities) моделей — чтобы сохранить несомненно ценные проявления авторегрессионного метода, но при этом не смущать пользователей неуместными (или даже откровенно вредными) высказываниями. Ведь компания серьёзно намерена в ближайшее время создать продвинутый ИИ и явно планирует достичь этой цели проверенным способом, постепенно улучшая модели линейки GPT — без коренного изменения их архитектуры. Другое дело, насколько удастся осуществить это благое намерение — и какой дополнительной ценой () за обработку стандартного запроса обернётся его реализация. Однако проблемы такого масштаба, судя по всему, будут решаться поэтапно; в полном соответствии с тем же авторегрессионным подходом: по мере возникновения — и с учётом опыта, полученного на предыдущих шагах.
Так что же это за метод такой?

Источник: создано искусственным интеллектом с применением архитектуры FLUX.1
⇡#Статистика, бездушная ты
В современной обработке последовательностей искусственным интеллектом — будь то связная речь, пиксельные массивы или музыкальные партитуры — центральное место занимает авторегрессионный метод. Его истоки уходят в математическую статистику, где он формировался задолго до возникновения машинного обучения как концепции. Фундаментальный принцип авторегрессии заключается в линейной связи каждого нового элемента временного ряда с заданным количеством (в идеале — со всеми) предшествующих значений этого же ряда. Хотя некоторые компоненты взвешенной суммы, описывающей эту зависимость, могут иметь нулевые коэффициенты (и фактически исключаться из влияния), формально каждый следующий элемент так или иначе определяется предыдущими. Современные языковые модели, основанные на авторегрессии (АрБЯМ), обычно используют трансформерные архитектуры, что позволяет достигать значительной нелинейности при генерации очередного токена. Однако сущность подхода неизменна: на формирование каждого элемента влияет ограниченное число предшественников — и совершенно не воздействуют будущие значения.
С одной стороны, это очевидное ограничение: алгоритм изначально не обладает полным контекстом при обработке запроса и лишь по мере достижения финальной точки выстраивает целостное представление. С другой — для формирования решений на подобные запросы данное ограничение не играет решающей роли: в конце концов, мы сами излагаем мысли последовательно — от буквы к слову, от слова к фразе, — а те, кто застал времена Netscape и Internet Explorer, помнят, как в этих ранних обозревателях (к тому же при медленных модемных подключениях того периода) изображения загружались постепенно, строка за строкой. Здесь можно было бы заметить, что человек, произносящий осмысленную речь, изначально имеет общее представление о своей мысли, равно как и художник не создаёт картину по одному пикселю, тогда как у языковой модели отсутствует и не может существовать «целостного осознания» того, что она в конечном счёте — токен за токеном — произведёт в качестве результата. Однако это возражение формально снимается обращением к техническим аспектам: пресловутое «целостное осознание» ИИ-алгоритм приобретает в ходе обучения, когда пропускает через многоуровневую нейросеть колоссальные объёмы данных, которые кто-то — в идеале люди; в худшем варианте, если обучающая выборка синтетическая, другие языковые модели — подготовил именно как упорядоченные цепочки информации. Упорядоченные согласно определённым принципам: грамматики, формальной логики, музыкальной гармонии и так далее.
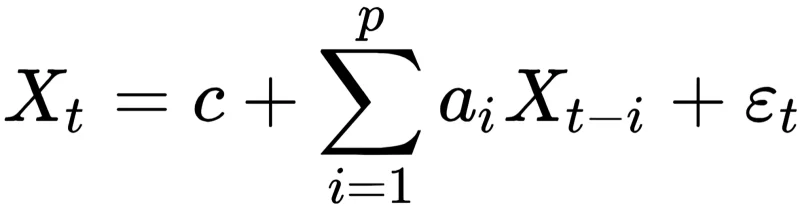
Математическое выражение авторегрессионной модели во многом напоминает формулы перемножения матриц, лежащие в основе современных систем искусственного интеллекта. Фактически здесь выполняется аналогичное взвешенное сложение (в рассматриваемом случае — предшествующих показателей временного ряда с определёнными коэффициентами, называемыми параметрами авторегрессии), однако присутствует дополнительный элемент, расположенный в конце формулы — он отображает воздействие случайных колебаний, привнося тем самым элемент вероятности в расчёт каждого последующего элемента ряда. Стоит отметить важную особенность: при вычислении t-го элемента суммирование осуществляется не в обратном порядке от t до 0, а от t − 1 до t − p, где обычно p ≠ t (источник: Wikimedia Commons)
Получается, что авторегрессионная языковая модель изначально содержит в своей архитектуре потенциальные ответы на все возможные запросы — они скрыто закодированы в виде весовых коэффициентов её перцептронов, сформированных в процессе обучения. Добавляемая на этапе генерации каждого нового элемента случайная составляющая придаёт машинным ответам привлекательное для человеческого восприятия разнообразие в нюансах. Правда, именно эта особенность может провоцировать возникновение галлюцинаций, но с ними приходится смириться: полученный результат (без учёта этого недостатка) слишком впечатляет. Следовательно, АрБЯМ, обработавшая в ходе обучения сотни миллионов токенизированных последовательностей, будет закономерно производить корректно структурированные тексты, изображения или музыкальные фрагменты. Этим объясняется, почему подавляющая часть крупных языковых моделей, предлагаемых сегодня ведущими разработчиками ИИ через облачные сервисы, построены по авторегрессионному принципу. Несмотря на очевидные ограничения и неидеальность данного подхода, он остаётся наиболее универсальным, хотя и требует значительных вычислительных ресурсов. Причём чем больше контекстное окно (длина цепочки предыдущих токенов, учитываемых моделью при генерации следующего), тем выше затраты. Логично, что генеративные модели, предназначенные для локального использования (будь то специализированные устройства вроде умных камер или домашние компьютеры), часто основываются на альтернативных архитектурах: например, генеративно-состязательных сетях (GAN) или моделях с латентными переменными. Однако даже в этих случаях, если применяются трансформеры, элементы авторегрессионного подхода, пусть в ограниченной форме, неизбежно присутствуют.
Почему же ответы, создаваемые именно авторегрессионными языковыми моделями, настолько привлекательны для реальных специалистов, что им готовы прощать и неизбежные искажения (обусловленные принципом работы алгоритма), и значительные затраты на обработку каждого запроса? Чтобы разобраться в этом, необходимо отойти от рассмотрения исключительно авторегрессионного метода и обратиться к индустрии искусственного интеллекта в целом — определить место и значение АрБЯМ в этой сфере. Тогда, будем надеяться, станут яснее как настойчивые доводы (особенно со стороны руководства OpenAI) в пользу дальнейшего развития именно этого направления генеративного ИИ, так и всё более ощутимые — на фоне несомненного улучшения качества ответов — последствия их фундаментальных недостатков.

Схема работы авторегрессионного метода для языковых моделей: кодировщик преобразует предыдущие части ввода в токены (это не всегда отдельные слова — возможны фразы из прошлых диалогов или целые текстовые блоки, что определяется размером контекстного окна), после чего блок стохастического предсказания выполняет взвешенное суммирование, формируя очередной прогнозируемый токен (источник: New York University)
⇡#Согласно алгоритму — безусловно
До того, как ИИ стал повсеместно распространённым, компьютерам преимущественно поручали выполнение задач по заранее заданному алгоритму: тщательно продуманному (в пределах компетенции разработчика, разумеется) набору команд на языке, понятном машине; такому описанию, которое детально определяет порядок шагов в виде цепочки — пусть и весьма разветвлённой — базовых операций. Программа, созданная таким способом, может быть проанализирована любым квалифицированным экспертом: даже в наиболее запутанной ситуации и без поясняющих пометок всегда возможно, внимательно изучив программный код (оригинальный либо восстановленный методами реверс-инжиниринга), точно установить, что именно и в какой момент предписывает выполнить алгоритм — и какова цель этого действия. Однако широкое внедрение искусственного интеллекта обнажило любопытный парадокс: хотя ИИ-модели конструируются и тренируются по вполне определённым принципам, принципы их работы зачастую остаются недоступными человеческому пониманию. Из-за этого возникает ощущение, будто логика изначально отсутствует — будто модель ИИ неалгоритмична, то есть не запрограммирована явным образом заранее. Хотя на уровне весов входов перцептронов, формирующих многоуровневую нейросеть, вся эта логика представлена в виде конкретных численных значений, которые приобрели своё текущее состояние в процессе глубинного обучения — осуществлявшегося как раз по строго определённому алгоритму.
Если алгоритм жёстко фиксирует процедуру принятия решений (изменяются лишь исходные данные), то искусственный интеллект в ходе обучения на обширных наборах информации самостоятельно формирует собственные механизмы выбора — однако, опять же, не произвольно, а в рамках изначально заданных разработчиками принципов. ИИ представляет собой комплекс слаженно работающих алгоритмов, которые могут перестраивать себя и даже порождать новые алгоритмические последовательности — в зависимости от команд оператора. Именно поэтому некорректно называть ИИ-модели неалгоритмическими: их внутренняя структура объективно выражается через упомянутые весовые коэффициенты, обладающие строгой организацией. Однако поскольку алгоритмы таких систем способны трансформироваться (и на практике постоянно трансформируются!) под влиянием поступающих данных — не только во время обучения, но и в процессе дообучения при взаимодействии с пользователем, а также генерировать новые алгоритмы в ходе этой адаптации, задача интерпретации их логики человеческим сознанием становится чрезвычайно сложной. «Объяснимый ИИ» (explainable AI, XAI) — отдельное научное направление в этой области, и уже очевидно, что предмет для его изучения объективно присутствует. В «чёрных ящиках», каковыми часто кажутся многослойные нейросети, не скрываются мистические оракулы; все происходящие там процессы, хоть и с трудом, но познаваемы и подчиняются — пусть усложняющимся и развивающимся — но всё тем же алгоритмам.

Авторегрессионной модели предложили создать ребус для слова PINEAPPLE. Решение вышло чрезмерно прямолинейным (избыточные надписи на изображении — сосна и яблоко легко опознаются), однако задача была выполнена (источник: ИИ-генерация на основе модели GPT-image-1)
В этом ракурсе становится понятнее, почему способность компьютерных систем, смоделированных в памяти, трансформироваться, приспосабливаться и обретать новые качества в процессе обработки поступающих данных получила название artificial intelligence: ведь английское слово intelligence изначально подразумевает сугубо практическую «возможность осваивать, осознавать и извлекать уроки из накопленного опыта». В русскоязычном контексте, вероятно, уместнее было бы применять не «интеллект» — термин, отягощённый серьёзным философским багажом — а определения «сообразительность» или «находчивость», однако исторически закрепился именно первый вариант. Задачи первых разработок ИИ были совершенно прозрачны, хотя с вычислительной точки зрения казались тогда невероятно сложными: освоить прогнозирование и выполнение комплексных операций, направленных на достижение заданного итога, опираясь на элементарные алгоритмы; например, побеждать людей в шахматных партиях. Или предлагать новые видео с учётом персональной истории просмотров конкретного юзера. Или взаимодействовать с пользователем на человеческом языке (natural language processing, NLP) — как это реализовывали голосовые ассистенты «Сири», «Алекса», «Кортана» и другие задолго до триумфального прорыва ChatGPT осенью 2022 года. Этот же прорыв стал возможен благодаря тому, что создатели OpenAI заложили в основу GPT-моделей принципиально иную, достаточно революционную для того периода методологию — генеративный искусственный интеллект (GenAI). Который, в отличие от предшественников, концентрируется не столько на анализе паттернов в массивах информации, сколько на творческом процессе. Создаёт — безусловно, опираясь на ранее обнаруженные закономерности — «уникальный» контент, исходя из выявленных при обучении без контроля (это принципиальный аспект) зависимостей и введённого пользователем запроса.
Слово «новый» заключено в кавычки не случайно: при наличии в обучающей выборке множества корректно размеченных изображений слонов и акул генеративная модель ИИ легко создаст по запросу вполне правдоподобную картинку существа с телом акулы на ногах слона, хотя подлинной новизны здесь нет — это всего лишь сочетание усвоенных нейросетью понятий, изначально существовавших в тренировочных данных по отдельности. Однако преуменьшать возможности генеративного искусственного интеллекта тоже не стоит: в гигантском потоке ежегодно публикуемых научных работ он может — при правильной настройке — выявлять взаимосвязи между исследованиями из разных дисциплин, которые люди обнаружили бы лишь случайно, поскольку узких специалистов, одновременно компетентных в обеих смежных областях, может просто не оказаться среди учёных.

«Нарисуй комикс на три панели о том, как лисички взяли спички, к морю синему пошли, море синее зажгли». — «Ни слова больше! Уже рисую!» (Источник: ИИ-генерация на основе модели GPT-image-1)




