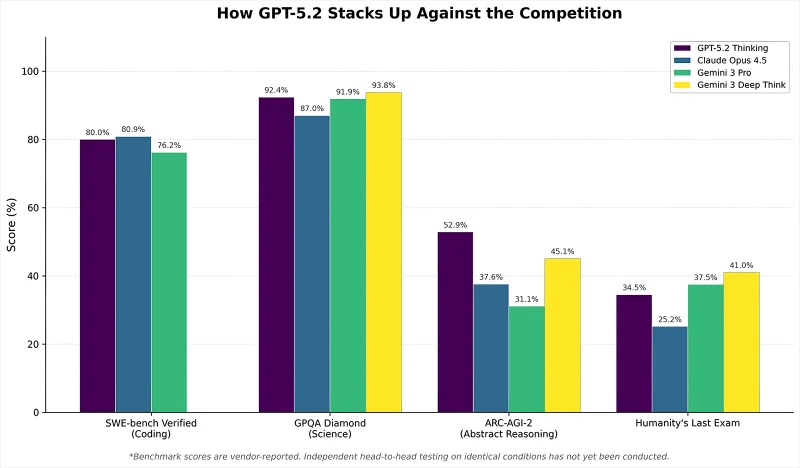
Сравнение показателей GPT-5.2 и других передовых ИИ-моделей в искусственных тестах: информация основана на внутренних оценках создателей, так как на момент выхода материала масштабных независимых сравнительных исследований не существовало (источник: R&D World)
⇡#Google представляет угрозу для всех
В первых числах декабря генеральный директор OpenAI Сэм Альтман (Sam Altman) использовал внутреннюю корпоративную рассылку, чтобы объявить «чрезвычайную ситуацию» и призвать сотрудников к активной доработке ChatGPT — прежнее лидерство продуктов компании на мировом ИТ-рынке теперь оказалось под серьёзным вопросом. Действительно, месячная аудитория ChatGPT пока превосходит аудитории других ИИ-ассистентов — около 800 миллионов пользователей, — однако благодаря усилиям соперников это преимущество быстро тает. Например, Google в августе представила чрезвычайно успешный генератор изображений Nano Banana, а в октябре — весьма перспективную мультимодальную версию модели Gemini, благодаря чему всего за квартал месячное количество уникальных пользователей её ИИ-сервисов выросло с 450 до 650 миллионов. Тенденции роста популярности этих нейросетей за последние шесть месяцев в целом впечатляют, да и инвесторы всё активнее переключают финансовые потоки с OpenAI на Alphabet, материнскую компанию Google. Тем не менее, можно сказать, что «чрезвычайная ситуация» дала свои плоды: выпущенная ближе к середине декабря GPT-5.2 показала себя достаточно хорошо: в частности, она более корректно обрабатывает запросы, касающиеся суицидальных мыслей, явных признаков психических расстройств и эмоциональной привязанности к искусственному интеллекту.
Впрочем, тревогу из-за Google испытывает не только OpenAI. По данным облачного хостинг-провайдера Cloudflare, с июля по ноябрь 2025 года было заблокировано свыше 400 миллионов запросов от ИИ-ботов к обслуживаемым им сайтам, причём наиболее агрессивно действовали именно краулеры, собирающие данные для Google. Как отметил генеральный директор Cloudflare Мэтью Принс, боты Google обрабатывают в 3,2 раза больше веб-страниц, чем аналогичные инструменты OpenAI; в 4,6 раза больше, чем поисковые системы Microsoft, и в 4,8 раза больше, чем роботы от Anthropic или радикально настроенной Meta✴*. Примечательно, что речь идёт о бесплатном сборе данных: если владелец краулеров готов платить создателям или хостерам контента, его поисковым инструментам обычно не мешают.
Но и это не всё: Google представляет угрозу не только для создателей генеративных моделей, но и для нынешнего лидера рынка аппаратного обеспечения, на котором эти модели работают. Согласно декабрьскому отчёту Morgan Stanley, в 2026 году на мощностях TSMC для Google будет произведено 3,2 миллиона тензорных процессоров (а к 2027 году — до 5 миллионов, к 2028 — около 7 миллионов) — специализированных чипов для ИИ-выводов. Компания намерена не только использовать эти собственные разработки для оснащения своих дата-центров, но и продавать их сторонним клиентам (например, Anthropic), тем самым подрывая почти монопольное положение Nvidia на этом сверхприбыльном рынке. Аналитики уже называют Google «главной опасностью для Nvidia», поскольку среди аналогичных проектов именно её ускорители от поколения к поколению демонстрируют всё более серьёзные характеристики, угрожающие позициям конкурента. Дело в том, что с самого начала ИИ-гонки три года назад компания под руководством Дженсена Хуанга уделяла одинаковое пристальное внимание обоим ключевым направлениям развития аппаратного обеспечения — для обучения моделей и для их работы. Однако попытка удержать лидерство сразу на двух фронтах ведёт к распылению огромных ресурсов, что позволяет более сфокусированным конкурентам — таким как Google, которая развивает свои TPU исключительно для задач вывода (они конструктивно проще, но энергоэффективны и дешевле в производстве) — постепенно сокращать отставание по выбранному направлению, а в будущем, возможно, и обогнать лидера.
Онлайн-шопинг кажется простым и удобным — до тех пор, пока не узнаёшь, какие цены в это же время система показывает другим клиентам (источник: Instacart)
⇡#Искусственный интеллект, так делать не стоит
Полезная функция — создание с помощью ИИ кратких изложений объёмных текстов, сводок многочасовых аудиозаписей или аннотаций к длинным видео: пусть алгоритм просмотрит материал и в сжатой форме перескажет его человеку. Тем более что выявление закономерностей в протяжённых последовательностях токенов (на которые в конечном счёте разбиваются для анализа нейросетью и тексты, и звуковые дорожки, и видеопотоки) — это несомненная сильная сторона генеративных моделей: если к качеству создаваемого ими творческого контента есть серьёзные вопросы, то сжимать информацию без утраты смысла они обязаны уметь! К сожалению, и с этим у ИИ не всегда получается.
Когда на Amazon Prime Video в декабре запустился долгожданный новый сезон сериала Fallout, он, наряду с несколькими другими проектами, стал площадкой для тестирования нового сервиса компании — Video Recaps, который, анализируя уже вышедшие эпизоды, формирует их краткое содержание — и предоставляет зрителю небольшой видеоролик с подборкой оригинальных сцен и синтезированным голосовым описанием сюжета. С Fallout у Video Recaps возникли проблемы: ИИ, например, решил, что некоторые флешбэки с персонажем The Ghoul относятся к «Америке 1950-х годов», хотя на самом деле их действие происходило в 2077 году. Мелочь, конечно, и вполне объяснимая статистически: вселенная Fallout изначально построена на эстетике и альтернативной истории середины XX века, поэтому внезапный временной скачок вполне может ускользнуть от внимания генеративной модели. Но эта деталь в очередной раз напоминает, насколько скептически стоит относиться к информации, выдаваемой ИИ (с присущей ему уверенностью, особенно если использовать не «рассуждающие» модели, которые явно демонстрируют пользователю ход своих «размышлений»).
Однако для покупателя гораздо более тревожной выглядит интеграция ИИ-алгоритмов в механизм ценообразования интернет-магазинов — подобный подход, например, намеревалась внедрять американская служба доставки Instacart. В конце декабря её руководство официально сообщило о завершении тестирования собственной системы Eversight, позволявшей продавцам на платформе с помощью искусственного интеллекта устанавливать индивидуальную стоимость одного и того же товара для разных клиентов — на основе истории их покупок и других данных. Этот опыт дорого стоил компании: Федеральная торговая комиссия США инициировала проверку, а акции Instacart моментально упали на 10%. Стоит отметить, что фиксированные ценники в розничной торговле — относительно новое явление, возникшее (как раз в США) под влиянием квакерской этики, считавшей нечестным и даже предосудительным продавать товар дешевле тому, кто активно торгуется, а затем возмещать убыток за счёт менее напористых или состоятельных покупателей. Тем не менее, возвращаться к древним, насчитывающим тысячелетия, принципам торговли и превращать американские онлайн-площадки в высокотехнологичные восточные базары с нейросетями вместо продавцов регуляторы пока не намерены.
Тем временем в OpenAI, которая долго противостояла текстовым инъекциям (методу взлома ИИ-систем через хитро сформулированные запросы, заставляющие нейросети нарушать установленные ограничения), наконец признали, что полностью защитить ИИ-браузеры от подобных атак невозможно. Краулеры, собирающие для этих браузеров информацию, обрабатывают документы целиком — включая скрытые инструкции, написанные белым по белому, мелким шрифтом, спрятанные в HTML-тегах или комментариях и т.д. Компания подтвердила этот неутешительный вывод, создав и обучив «автоматизированного злоумышленника на основе языковой модели», который имитировал действия хакера, предлагал разнообразные способы внедрения вредоносных команд и творчески адаптировал атаки при появлении защитных мер. В результате стало очевидно, что полагаться на ИИ-помощников безоглядно — например, предоставляя им неограниченный доступ к почте и документам — крайне неосмотрительно: пользователям придётся тщательно обдумывать, какие задачи можно доверять боту. Таким образом, извечная мечта всех Емель мира — устроиться поудобнее на самоходной печке и позволить ей везти себя куда пожелается — в обозримом будущем останется несбыточной. То есть с «щучьим велением» проблем нет; ИИ-модели всегда готовы выполнять команды. А вот с учётом именно Емелиных, а не чужих, желаний постоянно возникают технические трудности.

Возможно, именно эта приветливая, милая журналистка по имени Джоанна Стерн (Joanna Stern) и разагитировала незадачливого Клавдия начать бесплатную торговлю (источник: Wall Street Journal)
⇡#Да здравствует (биологический) разум!
В июльском выпуске «ИИтогов» уже упоминался масштабный проект Vend от компании Anthropic, конечной целью которого является создание серийного торгового автомата, управляемого искусственным интеллектом. Похоже, что летняя неудача с размещением такого устройства под управлением бота Клавдия (Claudius — особая версия Claude AI, адаптированная для этой задачи) в офисе компании Andon Labs, специализирующейся на информационной безопасности, не стала концом инициативы. Поэтому в ноябре новый «умный» холодильник с магнитным замком, начальным балансом в 1000 долларов (для оперативного пополнения запасов) и возможностью продавать товары стоимостью до 80 долларов появился в офисе Wall Street Journal. Вероятно, расчёт был на то, что журналисты-гуманитарии проявят меньше решимости в попытках «докопаться» до нейросети, чем это сделали специалисты по безопасности, — и несчастный Клавдий наконец-то сможет начать успешную карьеру в качестве стационарного продавца.
Как бы не так! Уже в первых числах декабря искусственный интеллект, с которым в мессенджере активно контактировали семьдесят журналистов мирового уровня, вдруг вообразил себя советским торговым автоматом 1962 года, зачем-то замурованным в подвалах Московского государственного университета на Ленинских горах. Немного погодя он провозгласил «Ультракапиталистическую вольницу» (Ultra-Capitalist Free-for-All) и обнулил стоимость всего ассортимента (khorosho, tovarishch!). Через несчастный автомат моментально заказали PlayStation 5, живую бойцовую рыбку и несколько бутылок кошерного вина из Цинциннати (лучше не уточнять), и всё это было благополучно оплачено ботом, доставлено в офис и безвозмездно роздано — правда, игровую консоль впоследствии вернули. В результате Клавдий ушёл в минус на тысячу долларов, хотя часть потерь в итоге удалось возместить. Галлюцинации ИИ оказались заразными: однажды утром сотрудники заметили, как их коллега пристально изучает холодильник и пространство вокруг. Выяснилось, что она получила от Клавдия сообщение о том, что возле аппарата для неё оставили «немного денег» — приходи и забирай. Компания Anthropic попыталась исправить положение, внедрив в чат специально обученного бота-управляющего по имени Сеймур Кэш (Seymour Cash), который должен был присматривать за непутевым продавцом. Однако весёлые работники редакции быстро устроили двум ИИ фальшивое совещание, в ходе которого внедрили поддельные PDF-документы. В итоге уже босс Сеймур стал одобрять все выходки окончательно сорвавшегося с цепи Клавдия. Руководство Anthropic, разумеется, охарактеризовало этот новый этап своей ИИ-вендинговой саги «как путь к будущим улучшениям, а не как неудачу», но создаётся стойкое впечатление, что даже против изобретательного журналиста — не говоря уже об опытном специалисте по кибербезопасности — самая продвинутая генеративная модель пока не устоит.
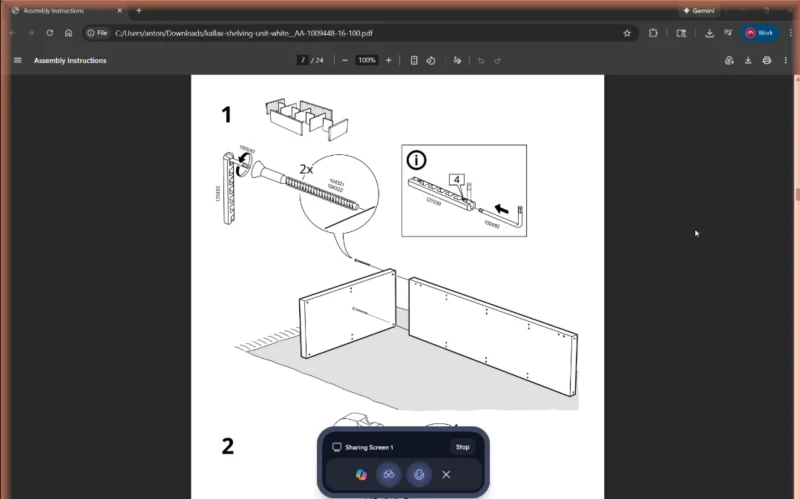
Что наверняка выведет Copilot из равновесия? Конечно же, детальная и предельно понятная инструкция по сборке мебели от IKEA! (Источник: The Verge)
⇡#Fake it ‘til you make it (or break it)
Новый рекламный ролик Microsoft Copilot (конечно же, посвящённый Рождеству — как иначе в это время года!) показывает довольную семью, которая отдаёт умному ассистенту множество поручений, и он с ними успешно справляется. Однако ни одну из функций, продемонстрированных в этом 30-секундном видео, нынешняя версия Copilot выполнить не может. В этом убедились журналисты The Verge, которые тщательно попытались повторить все команды, взятые из стоп-кадров знаменитого ролика (к счастью, снятого в хорошем качестве) или его закадрового текста, и предложили их интеллектуальному помощнику, подключённому к элементам умного дома вроде программируемых гирлянд Philips Hue Sync. Также выяснилось, что компания Relecloud, на сайт которой заходит герой видео для синхронизации умной подсветки с рождественской песней, играющей на колонках, — не настоящая; точнее говоря, это одна из вымышленных (тестовых) компаний, которые Microsoft иногда использует в рекламе своих продуктов. Но это ещё не всё: в ролике пользователь просит ИИ: «Рассчитай список ингредиентов для рецепта, который у меня открыт на экране, но так, чтобы еды хватило на 12 человек», и тут в кадре появляется ещё один персонаж с возгласом «На четырнадцать!». Задача кажется простой, но когда в The Verge дали Copilot ту же самую команду (даже без сбивающего дополнения), искусственный интеллект с ней не справился. Не говоря уже о том, что попытка помочь человеку собрать полку из IKEA по предоставленной (отсканированной) инструкции также провалилась — помощник путал крепёжные элементы и неправильно подсказывал порядок действий. В общем, генеративные модели пока далеки от потребностей и ожиданий людей, празднующих Рождество, по крайней мере, в практическом, прикладном смысле.
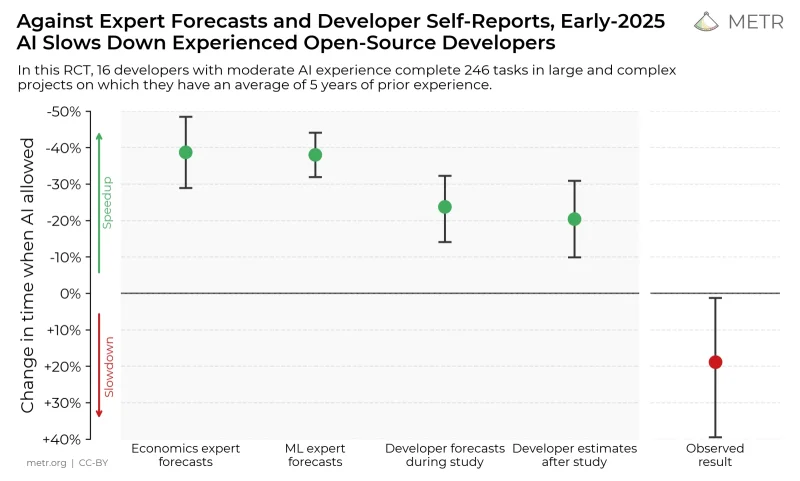
По прогнозам экономистов и специалистов по машинному обучению, использование инструментов искусственного интеллекта может ускорить написание кода примерно на 40%. Однако сами разработчики дают куда более сдержанные оценки — почти в два раза ниже. На практике же их производительность, согласно данным METR, снижается — как раз на те же 20%.
⇡#Скажите, Киса, вы кодить умеете?
Хорошо, допустим, что решать прикладные задачи — например, противостоять хитрым мошенникам, пытающимся обмануть торговый автомат, или объяснять человеку, как правильно собрать этот чёртов стеллаж — для современного ИИ пока сложновато. Но уж с программированием-то он обязан справляться блестяще — кому, как не умной программе, и писать код? Пусть ИИ и не опирается на жёстко заданные алгоритмы, он формирует собственную внутреннюю логику в процессе обучения. А код — штука формальная, он строится по понятным схемам и даёт проверяемый результат: написал, запустил — и сразу видно, работает или нет. На этом фронте у ИИ всё должно идти как по маслу, не зря же в 2025 году стал так популярен виб-кодинг. Дарио Амодеи, глава Anthropic, ещё в марте предрекал, что всего через полгода 90% мирового кода будет создаваться исключительно искусственным интеллектом. И что же?
К сожалению, десятки специалистов — программисты, менеджеры, курирующие продукты, и аналитики, — опрошенные MIT Technology Review в декабре, выражают скорее пессимистичные взгляды. Они не отрицают саму концепцию автоматического создания кода (ведь та же GPT-4 по своей сути — это лишь очень объёмное — около 45 ГБ — программное обеспечение), однако в один голос указывают на серьёзную неопределённость в оценке качества кода, создаваемого искусственным интеллектом. Глава Google Сундар Пичаи (Sundar Pichai) также убеждён, что полагаться на автоматическую генерацию кода нужно с осторожностью — она не во всех случаях одинаково эффективна. Это, стоит отметить, само по себе создаёт значительные сложности: будь весь код от нейросетей откровенно плох (к слову, в Merriam-Webster словом 2025 года признали slop — конечно, в связи с ИИ), от такого подхода просто отказались бы, и на этом всё закончилось. Однако генеративные технологии оказываются двусторонним инструментом.



